

Speech know-how nonetheless has an information distribution drawback. Automated Speech Recognition (ASR) and Textual content-to-Speech (TTS) techniques have improved quickly for high-resource languages, however many African languages stay poorly represented in open corpora. A workforce of researchers from Google and different collaborators introduce WAXAL, an open multilingual speech dataset for African languages protecting 24 languages, with an ASR element constructed from transcribed pure speech and a TTS element constructed from studio-quality single-speaker recordings.
WAXAL is structured as two separate sources as a result of ASR and TTS have completely different information necessities. The ASR aspect is designed round numerous audio system, pure environments, and spontaneous language manufacturing. The TTS aspect is designed round managed recording situations, phonetically balanced scripts, and cleaner single-speaker audio fitted to synthesis. That separation is technically necessary: a dataset that’s helpful for strong recognition in noisy real-world settings is often not the identical dataset that produces robust single-speaker TTS fashions.
How the ASR information was collected
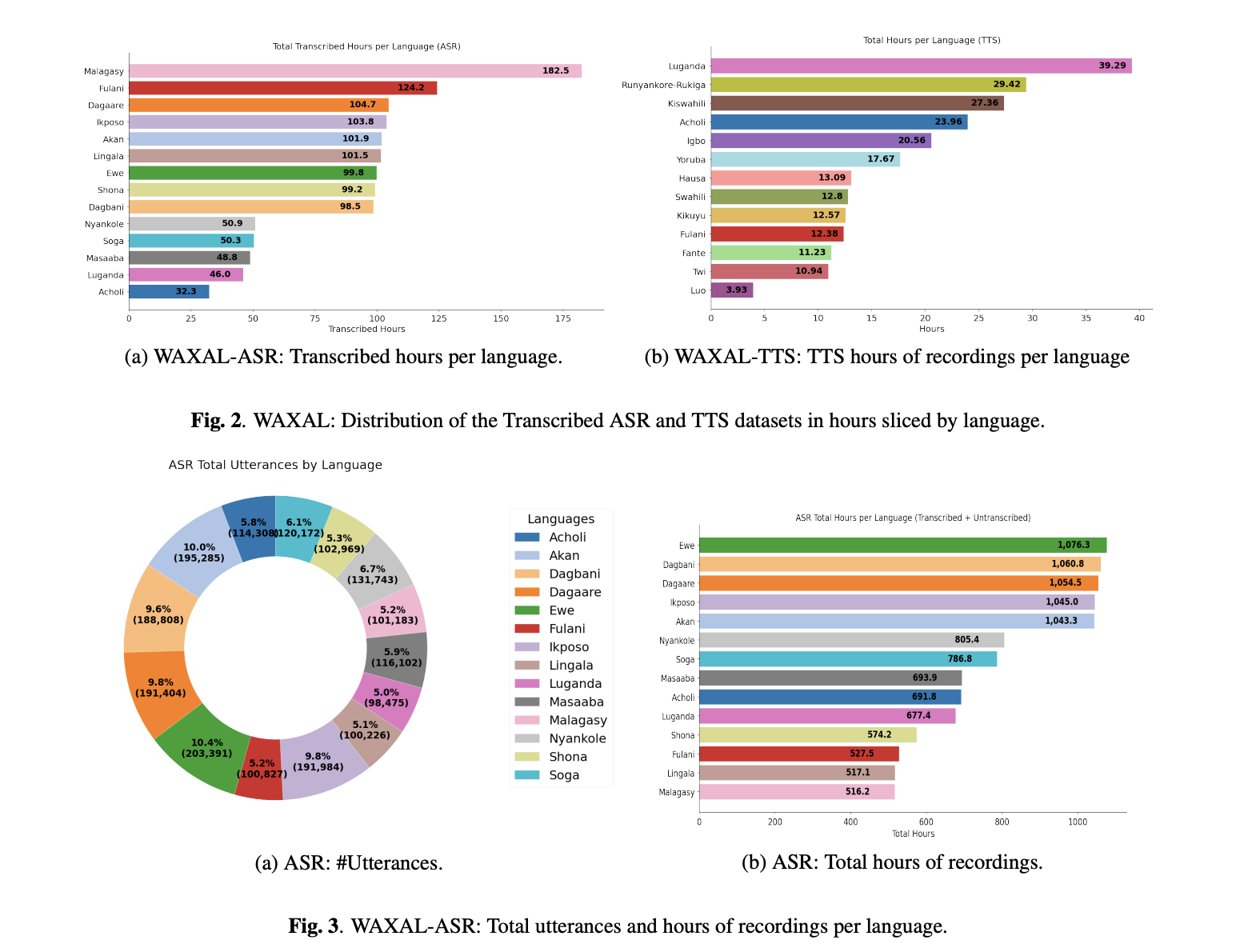
The ASR portion of WAXAL was collected utilizing image-prompted speech. Audio system have been proven photographs and requested to explain what they noticed of their native language, which is a extra pure setup than easy prompted studying. Recordings have been captured in audio system’ pure environments, every with a minimal period of 15 seconds. The gathering course of additionally tracked metadata equivalent to speaker age, gender, language, and recording setting. Solely a subset of the total collected audio was transcribed: the analysis workforce states that the present ASR launch contains transcriptions for about 10% of the overall recorded audio. These transcriptions have been produced by paid native linguistic consultants, utilizing native scripts the place accessible and English-alphabet transliteration in any other case.
That is necessary for anybody constructing multilingual ASR techniques. Picture-prompted speech tends to seize extra pure lexical and syntactic variation than tightly scripted studying, but it surely additionally makes transcription more durable and will increase variation throughout audio system, domains, and acoustic situations. WAXAL leans into that tradeoff quite than avoiding it. The consequence shouldn’t be a wonderfully clear benchmark dataset; it’s nearer to a field-collected multilingual ASR information with actual variability baked in.
How the TTS information was collected
The TTS aspect of WAXAL was constructed very otherwise. The TTS dataset was designed for high-quality, single-speaker artificial voices. For every goal language, the analysis workforce created a phonetically balanced script of roughly 108,500 phrases. They contracted 72 neighborhood individuals, evenly break up between female and male voice actors, and recorded them in skilled studio-like environments to scale back background noise and protect audio constancy. The goal was roughly 16 hours of unpolluted edited audio per voice actor.
That is the best design selection for synthesis. TTS fashions care way more about consistency in pronunciation, recording situations, microphone high quality, and speaker identification than ASR techniques do. WAXAL subsequently avoids the widespread mistake of treating ‘speech information’ as a single class, when in observe ASR and TTS pipelines need very completely different supervision alerts.
Key Takeaways
- WAXAL is an open multilingual speech corpus constructed for low-resource African language ASR and TTS.
- The ASR information makes use of image-prompted, pure speech collected in real-world environments.
- The TTS information makes use of studio-quality, single-speaker recordings with phonetically balanced scripts.
Try Paper and Dataset right here. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be part of us on telegram as nicely.

Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and information engineering, Michal excels at reworking complicated datasets into actionable insights.

