
")
Why Doc OCR Nonetheless Stays a Exhausting Engineering Drawback? What does it take to make OCR helpful for actual paperwork as a substitute of unpolluted demo pictures? And may a compact multimodal mannequin deal with parsing, tables, formulation, and structured extraction with out turning inference right into a useful resource bonfire?
That’s the downside focused by GLM-OCR, launched by researchers from Zhipu AI and Tsinghua College. The analysis staff presents GLM-OCR as a 0.9B-parameter compact multimodal mannequin for doc understanding. It combines a 0.4B CogViT visible encoder, a light-weight cross-modal connector, and a 0.5B GLM language decoder. The said purpose is to stability doc recognition high quality with decrease latency and decrease computational price than bigger multimodal methods.
Conventional OCR methods are sometimes good at plain textual content transcription, however they battle when paperwork comprise combined layouts, tables, formulation, code blocks, seals, and structured fields. Latest multimodal massive language fashions enhance doc understanding, however the analysis staff argue that their measurement and normal autoregressive decoding make them costly for edge deployment and large-scale manufacturing. GLM-OCR is positioned as a smaller system constructed for these deployment constraints reasonably than as a general-purpose vision-language mannequin tailored to OCR as an afterthought.
A Compact Structure Constructed for OCR Workloads
A key technical level for this analysis is using Multi-Token Prediction (MTP). Commonplace autoregressive decoding predicts one token at a time, which isn’t splendid for OCR-style duties the place outputs are sometimes deterministic and domestically structured. GLM-OCR as a substitute predicts a number of tokens per step. The mannequin is skilled to foretell 10 tokens per step and generates 5.2 tokens per decoding step on common at inference time, yielding about 50% throughput enchancment. To maintain reminiscence overhead manageable, the implementation makes use of a parameter-sharing scheme throughout the draft fashions.
Two-Stage Format Parsing As a substitute of Flat Web page Studying
On the system degree, GLM-OCR adopts a two-stage pipeline. The primary stage makes use of PP-DocLayout-V3 for format evaluation, which detects structured areas on the web page. The second stage performs parallel region-level recognition over these detected areas. That is necessary as a result of the mannequin isn’t merely studying a complete web page left-to-right as a generic vision-language mannequin would possibly. It first breaks down the web page into semantically significant areas, which improves effectivity and makes the system extra strong on paperwork with difficult layouts.
Doc Parsing and KIE Use Totally different Output Paths
The structure additionally separates two associated doc duties. For doc parsing, the pipeline makes use of format detection and area processing to provide structured outputs corresponding to Markdown and JSON. For Key Data Extraction (KIE), the analysis staff describes a distinct path: the total doc picture is fed to the mannequin with a job immediate, and the mannequin instantly generates JSON containing the extracted fields. That distinction issues as a result of GLM-OCR isn’t offered as a single monolithic page-to-text mannequin. It’s a structured technology system with completely different working modes relying on the duty.
A 4-Stage Coaching Pipeline with Job-Particular Rewards
The coaching recipe is cut up into 4 levels. Stage 1 trains the imaginative and prescient encoder on image-text pairs and grounding or retrieval knowledge. Stage 2.1 performs multimodal pretraining on image-text, doc parsing, grounding, and VQA knowledge. Stage 2.2 provides the MTP goal. Stage 3 is supervised fine-tuning on OCR-specific duties together with textual content recognition, method transcription, desk construction restoration, and KIE. Stage 4 applies reinforcement studying utilizing GRPO. The reward design is task-specific: Normalized Edit Distance for textual content recognition, CDM rating for method recognition, TEDS rating for desk recognition, and field-level F1 for KIE, together with structural penalties corresponding to repetition penalties, malformed construction penalties, and JSON validation constraints.
Benchmark Outcomes Present Robust Efficiency, With Necessary Caveats
On public benchmarks, GLM-OCR experiences sturdy outcomes throughout a number of doc duties. It scores 94.6 on OmniDocBench v1.5, 94.0 on OCRBench (Textual content), 96.5 on UniMERNet, 85.2 on PubTabNet, and 86.0 on TEDS_TEST. For KIE, it experiences 93.7 on Nanonets-KIE and 86.1 on Handwritten-KIE. The analysis staff notes that outcomes for Gemini-3-Professional and GPT-5.2-2025-12-11 are proven just for reference and are excluded from the best-score rating, which is a crucial element when decoding claims about mannequin management.
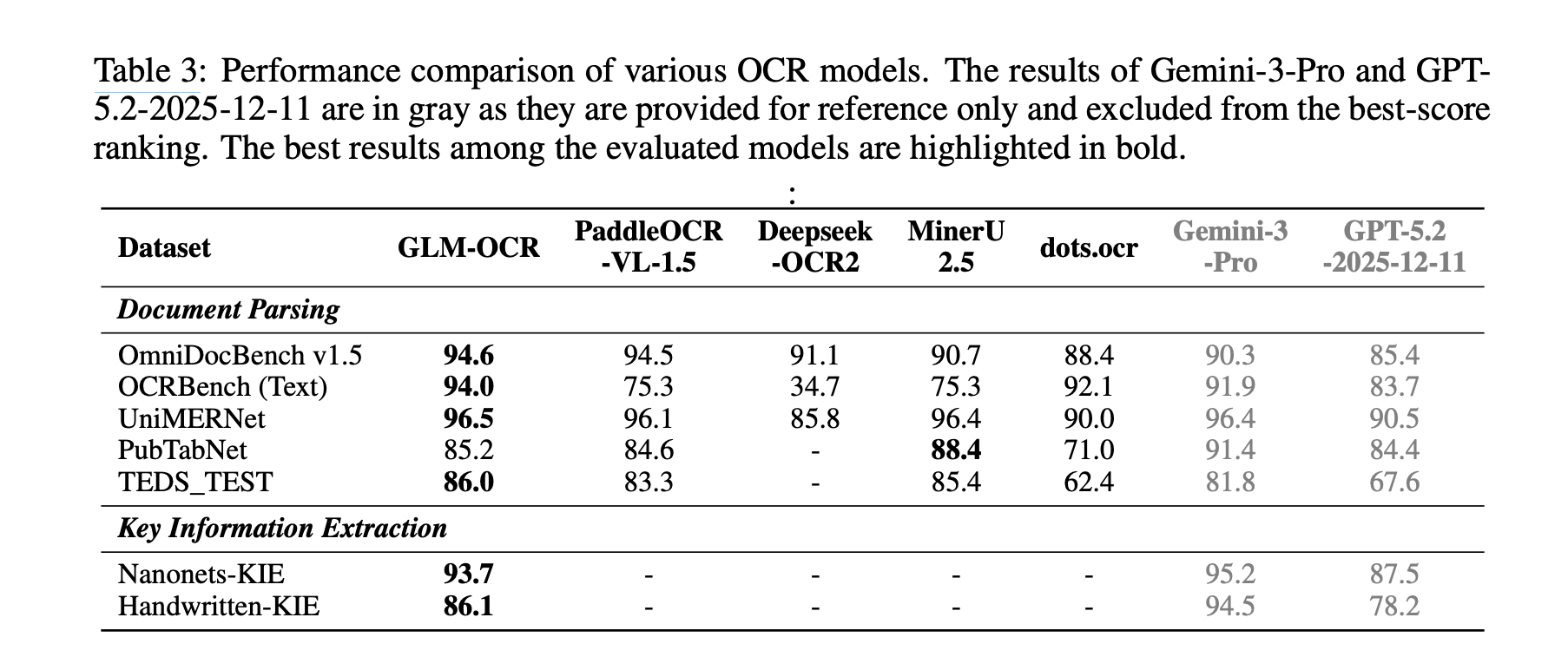
The benchmark story is robust, however it wants cautious phrasing. GLM-OCR achieves the very best reported scores among the many evaluated non-reference fashions on OmniDocBench v1.5, OCRBench (Textual content), UniMERNet, and TEDS_TEST. On PubTabNet, nonetheless, it does not lead general; MinerU 2.5 experiences 88.4 versus GLM-OCR’s 85.2. For KIE, GLM-OCR outperforms the listed open-source rivals within the above desk, however Gemini-3-Professional scores greater on each Nanonets-KIE and Handwritten-KIE within the reference column. So the reserach staff helps a robust aggressive declare, however not a blanket ‘finest at all the things’ declare.
Deployment Particulars
The analysis staff state that GLM-OCR helps vLLM, SGLang, and Ollama, and may be fine-tuned by LLaMA-Manufacturing facility. Additionally they report throughput of 0.67 pictures/s and 1.86 PDF pages/s underneath their analysis setup. As well as, they describe a MaaS API priced at 0.2 RMB per million tokens, with instance price estimates for scanned pictures and simple-layout PDFs. These particulars counsel that GLM-OCR is being framed as each a analysis mannequin and a deployable system.
Key Takeaways
- GLM-OCR is a compact 0.9B multimodal OCR mannequin constructed with a 0.4B CogViT encoder and 0.5B GLM decoder.
- It makes use of Multi-Token Prediction (MTP) to enhance decoding effectivity, reaching 5.2 tokens per step on common and about 50% greater throughput.
- The mannequin makes use of a two-stage pipeline: PP-DocLayout-V3 handles format evaluation, then GLM-OCR performs parallel region-level recognition.
- It helps each doc parsing and KIE: parsing outputs Markdown/JSON, whereas KIE instantly generates JSON from the total doc picture.
- Benchmark outcomes are sturdy however not common wins: GLM-OCR leads a number of reported non-reference benchmarks, however MinerU 2.5 is greater on PubTabNet, and Gemini-3-Professional is greater on the reference-only KIE scores.
Try Paper, Repo and Mannequin Web page. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as nicely.

