

Within the high-stakes world of AI, ‘Context Engineering’ has emerged as the most recent frontier for squeezing efficiency out of LLMs. Trade leaders have touted AGENTS.md (and its cousins like CLAUDE.md) as the final word configuration level for coding brokers—a repository-level ‘North Star’ injected into each dialog to information the AI by advanced codebases.
However a current research from researchers at ETH Zurich simply dropped a large actuality examine. The findings are fairly clear: in the event you aren’t deliberate together with your context information, you’re seemingly sabotaging your agent’s efficiency whereas paying a 20% premium for the privilege.
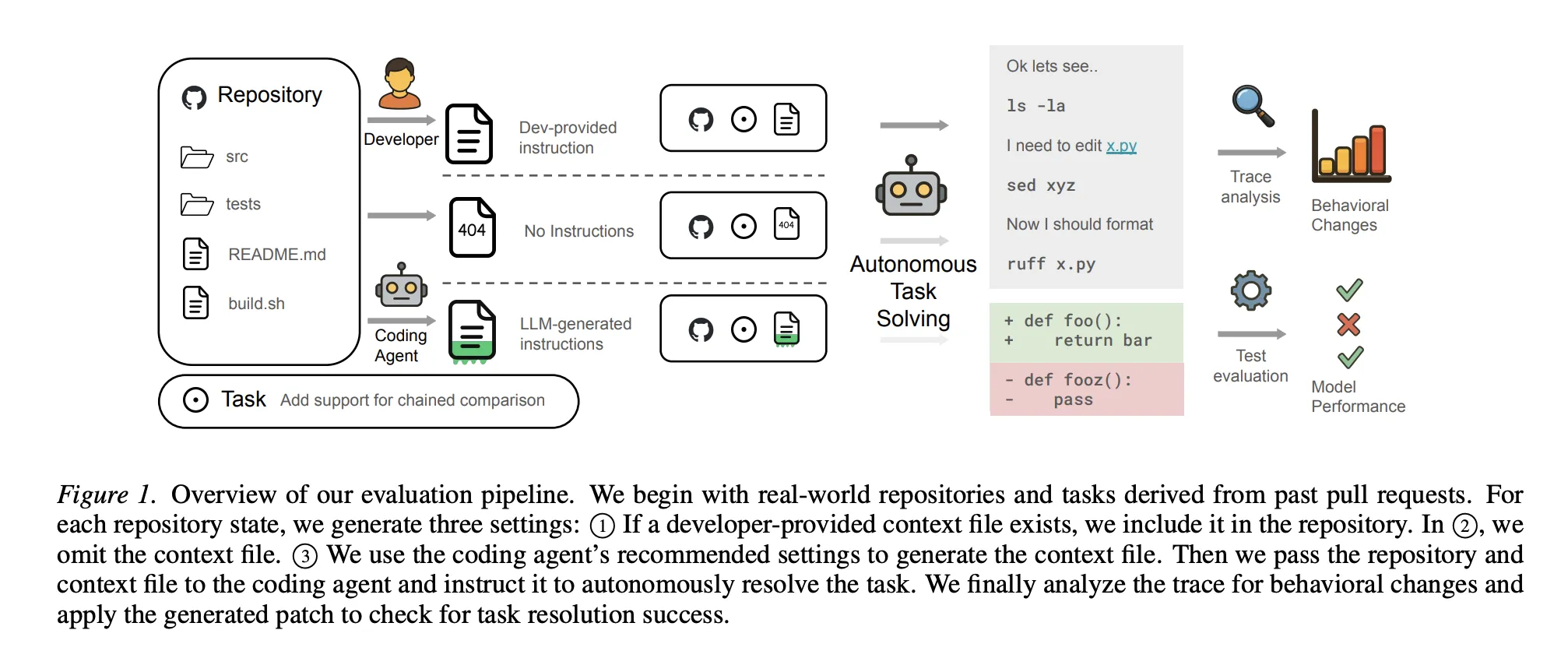
The Knowledge: Extra Tokens, Much less Success
The ETH Zurich analysis workforce analyzed coding brokers like Sonnet-4.5, GPT-5.2, and Qwen3-30B throughout established benchmarks and a novel set of real-world duties known as AGENTBENCH. The outcomes had been surprisingly lopsided:
- The Auto-Generated Tax: Mechanically generated context information really diminished success charges by roughly 3%.
- The Value of ‘Assist‘: These information elevated inference prices by over 20% and necessitated extra reasoning steps to unravel the identical duties.
- The Human Margin: Even human-written information solely offered a marginal 4% efficiency acquire.
- The Intelligence Cap: Curiously, utilizing stronger fashions (like GPT-5.2) to generate these information didn’t yield higher outcomes. Stronger fashions usually have sufficient ‘parametric information’ of widespread libraries that the additional context turns into redundant noise.
Why ‘Good’ Context Fails
The analysis workforce highlights a behavioral lure: AI brokers are too obedient. Coding brokers are inclined to respect the directions present in context information, however when these necessities are pointless, they make the duty more durable.
As an illustration, the researchers discovered that codebase overviews and listing listings—a staple of most AGENTS.md information—didn’t assist brokers navigate quicker. Brokers are surprisingly good at discovering file constructions on their very own; studying a handbook itemizing simply consumes reasoning tokens and provides ‘psychological’ overhead. Moreover, LLM-generated information are sometimes redundant if you have already got respectable documentation elsewhere within the repo.

The New Guidelines of Context Engineering
To make context information really useful, you’ll want to shift from ‘complete documentation’ to ‘surgical intervention.’
1. What to Embody (The ‘Important Few’)
- The Technical Stack & Intent: Clarify the ‘What’ and the ‘Why.’ Assist the agent perceive the aim of the undertaking and its structure (e.g., a monorepo construction).
- Non-Apparent Tooling: That is the place
AGENTS.mdshines. Specify methods to construct, take a look at, and confirm modifications utilizing particular instruments likeuvas an alternative ofpiporbunas an alternative ofnpm. - The Multiplier Impact: The information reveals that directions are adopted; instruments talked about in a context file are used considerably extra usually. For instance, the software
uvwas used 160x extra regularly (1.6 occasions per occasion vs. 0.01) when explicitly talked about.+1
2. What to Exclude (The ‘Noise’)
- Detailed Listing Bushes: Skip them. Brokers can discover the information they want with no map.
- Type Guides: Don’t waste tokens telling an agent to “use camelCase.” Use deterministic linters and formatters as an alternative—they’re cheaper, quicker, and extra dependable.
- Job-Particular Directions: Keep away from guidelines that solely apply to a fraction of your points.
- Unvetted Auto-Content material: Don’t let an agent write its personal context file with no human evaluate. The research proves that ‘stronger’ fashions don’t essentially make higher guides.
3. The way to Construction It
- Maintain it Lean: The final consensus for high-performance context information is underneath 300 traces. Skilled groups usually maintain theirs even tighter—underneath 60 traces. Each line counts as a result of each line is injected into each session.
- Progressive Disclosure: Don’t put all the pieces within the root file. Use the principle file to level the agent to separate, task-specific documentation (e.g.,
agent_docs/testing.md) solely when related. - Pointers Over Copies: As a substitute of embedding code snippets that can ultimately go stale, use pointers (e.g.,
file:line) to point out the agent the place to search out design patterns or particular interfaces.
Key Takeaways
- Unfavorable Influence of Auto-Era: LLM-generated context information have a tendency to cut back job success charges by roughly 3% on common in comparison with offering no repository context in any respect.
- Vital Value Will increase: Together with context information will increase inference prices by over 20% and results in a better variety of steps required for brokers to finish duties.
- Minimal Human Profit: Whereas human-written (developer-provided) context information carry out higher than auto-generated ones, they solely supply a marginal enchancment of about 4% over utilizing no context information.
- Redundancy and Navigation: Detailed codebase overviews in context information are largely redundant with current documentation and don’t assist brokers discover related information any quicker.
- Strict Instruction Following: Brokers usually respect the directions in these information, however pointless or overly restrictive necessities usually make fixing real-world duties more durable for the mannequin.
Take a look at the Paper. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be part of us on telegram as effectively.


