

Cohere AI Labs has launched Tiny Aya, a household of small language fashions (SLMs) that redefines multilingual efficiency. Whereas many fashions scale by growing parameters, Tiny Aya makes use of a 3.35B-parameter structure to ship state-of-the-art translation and technology throughout 70 languages.
The discharge consists of 5 fashions: Tiny Aya Base (pretrained), Tiny Aya International (balanced instruction-tuned), and three region-specific variants—Earth (Africa/West Asia), Fireplace (South Asia), and Water (Asia-Pacific/Europe).
The Structure
Tiny Aya is constructed on a dense decoder-only Transformer structure. Key specs embrace:
- Parameters: 3.35B whole (2.8B non-embedding)
- Layers: 36
- Vocabulary: 262k tokenizer designed for equitable language illustration.
- Consideration: Interleaved sliding window and full consideration (3:1 ratio) with Grouped Question Consideration (GQA).
- Context: 8192 tokens for enter and output.
The mannequin was pretrained on 6T tokens utilizing a Warmup-Steady-Decay (WSD) schedule. To take care of stability, the crew used SwiGLU activations and eliminated all biases from dense layers.
Superior Put up-training: FUSION and SimMerge
To bridge the hole in low-resource languages, Cohere used an artificial knowledge pipeline.
- Fusion-of-N (FUSION): Prompts are despatched to a ‘crew of academics’ (COMMAND A, GEMMA3-27B-IT, DEEPSEEK-V3). A choose LLM, the Fusor, extracts and aggregates the strongest elements of their responses.
- Area Specialization: Fashions have been finetuned on 5 regional clusters (e.g., South Asia, Africa).
- SimMerge: To forestall ‘catastrophic forgetting’ of world security, regional checkpoints have been merged with the worldwide mannequin utilizing SimMerge, which selects the perfect merge operators primarily based on similarity indicators.
Efficiency Benchmarks
Tiny Aya International persistently beats bigger or same-scale rivals in multilingual duties:
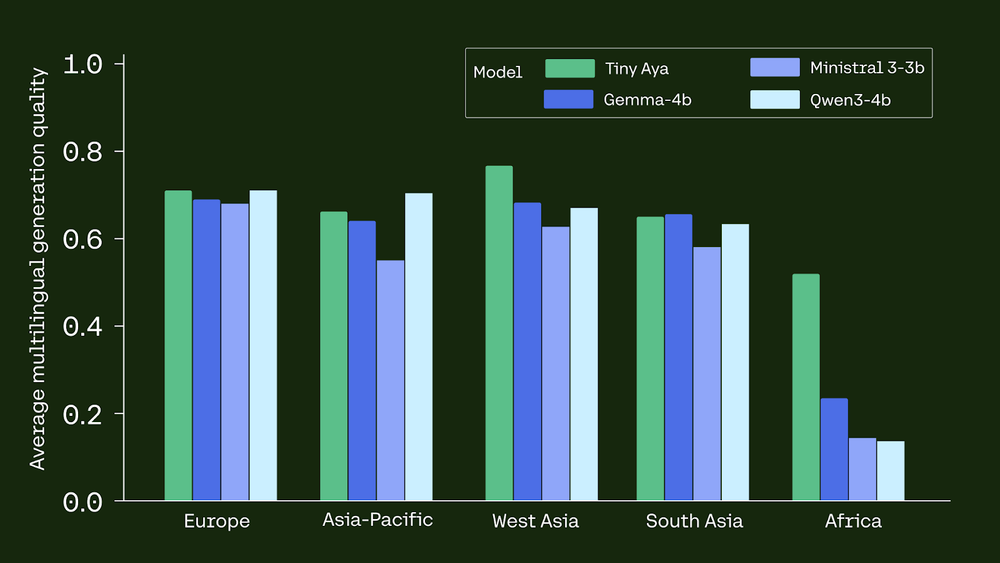
- Translation: It outperforms GEMMA3-4B in 46 of 61 languages on WMT24++.
- Reasoning: Within the GlobalMGSM (math) benchmark for African languages, Tiny Aya achieved 39.2% accuracy, dwarfing GEMMA3-4B (17.6%) and QWEN3-4B (6.25%).
- Security: It holds the best imply secure response fee (91.1%) on MultiJail.
- Language Integrity: The mannequin achieves 94% language accuracy, that means it not often switches to English when requested to answer in one other language.
On-Machine Deployment
Tiny Aya is optimized for edge computing. Utilizing 4-bit quantization (Q4_K_M), the mannequin suits in a 2.14 GB reminiscence footprint.
- iPhone 13: 10 tokens/s.
- iPhone 17 Professional: 32 tokens/s.
This quantization scheme ends in a minimal 1.4-point drop in technology high quality, making it a viable resolution for offline, non-public, and localized AI purposes.
Key Takeaways
- Environment friendly Multilingual Energy: Tiny Aya is a 3.35B-parameter mannequin household that delivers state-of-the-art translation and high-quality technology throughout 70 languages. It proves that huge scale will not be required for robust multilingual efficiency if fashions are designed with intentional knowledge curation.
- Progressive Coaching Pipeline: The fashions have been developed utilizing a novel technique involving Fusion-of-N (FUSION), the place a ‘crew of academics’ (like Command A and DeepSeek-V3) generated artificial knowledge. A choose mannequin then aggregated the strongest elements to make sure high-quality coaching indicators even for low-resource languages.
- Regional Specialization by way of Merging: Cohere launched specialised variants—Tiny Aya Earth, Fireplace, and Water—that are tuned for particular areas like Africa, South Asia, and the Asia-Pacific. These have been created by merging regional fine-tuned fashions with a worldwide mannequin utilizing SimMerge to protect security whereas boosting native language efficiency.
- Superior Benchmark Efficiency: Tiny Aya International outperforms rivals like Gemma3-4B in translation high quality for 46 of 61 languages on WMT24++. It additionally considerably reduces disparities in mathematical reasoning for African languages, attaining 39.2% accuracy in comparison with Gemma3-4B’s 17.6%.
- Optimized for On-Machine Deployment: The mannequin is very moveable and runs effectively on edge units; it achieves ~10 tokens/s on an iPhone 13 and 32 tokens/s on an iPhone 17 Professional utilizing Q4_K_M quantization. This 4-bit quantization format maintains prime quality with solely a minimal 1.4-point degradation.
Try the Technical particulars, Paper, Mannequin Weights and Playground. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.


