

Moonshot AI has launched Kimi K2.5 as an open supply visible agentic intelligence mannequin. It combines a big Combination of Consultants language spine, a local imaginative and prescient encoder, and a parallel multi agent system known as Agent Swarm. The mannequin targets coding, multimodal reasoning, and deep internet analysis with robust benchmark outcomes on agentic, imaginative and prescient, and coding suites.
Mannequin Structure and Coaching
Kimi K2.5 is a Combination of Consultants mannequin with 1T whole parameters and about 32B activated parameters per token. The community has 61 layers. It makes use of 384 specialists, with 8 specialists chosen per token plus 1 shared knowledgeable. The eye hidden measurement is 7168 and there are 64 consideration heads.
The mannequin makes use of MLA consideration and the SwiGLU activation operate. The tokenizer vocabulary measurement is 160K. The utmost context size throughout coaching and inference is 256K tokens. This helps lengthy instrument traces, lengthy paperwork, and multi step analysis workflows.
Imaginative and prescient is dealt with by a MoonViT encoder with about 400M parameters. Visible tokens are educated along with textual content tokens in a single multimodal spine. Kimi K2.5 is obtained by continuous pretraining on about 15T tokens of blended imaginative and prescient and textual content knowledge on prime of Kimi K2 Base. This native multimodal coaching is vital as a result of the mannequin learns joint construction over photos, paperwork, and language from the beginning.
The launched checkpoints assist customary inference stacks akin to vLLM, SGLang, and KTransformers with transformers model 4.57.1 or newer. Quantized INT4 variants can be found, reusing the strategy from Kimi K2 Considering. This permits deployment on commodity GPUs with decrease reminiscence budgets.
Coding and Multimodal Capabilities
Kimi K2.5 is positioned as a robust open supply coding mannequin, particularly when code technology is determined by visible context. The mannequin can learn UI mockups, design screenshots, and even movies, then emit structured frontend code with structure, styling, and interplay logic.
Moonshot reveals examples the place the mannequin reads a puzzle picture, causes concerning the shortest path, after which writes code that produces a visualized answer. This demonstrates cross modal reasoning, the place the mannequin combines picture understanding, algorithmic planning, and code synthesis in a single move.
As a result of K2.5 has a 256K context window, it could hold lengthy specification histories in context. A sensible workflow for builders is to combine design belongings, product docs, and present code in a single immediate. The mannequin can then refactor or lengthen the codebase whereas maintaining visible constraints aligned with the unique design.

Agent Swarm and Parallel Agent Reinforcement Studying
A key characteristic of Kimi K2.5 is Agent Swarm. This can be a multi agent system educated with Parallel Agent Reinforcement Studying, PARL. On this setup an orchestrator agent decomposes a fancy objective into many subtasks. It then spins up area particular sub brokers to work in parallel.
Kimi crew stories that K2.5 can handle as much as 100 sub brokers inside a job. It helps as much as 1,500 coordinated steps or instrument calls in a single run. This parallelism provides about 4.5 instances sooner completion in contrast with a single agent pipeline on broad search duties.
PARL introduces a metric known as Essential Steps. The system rewards insurance policies that cut back the variety of serial steps wanted to unravel the duty. This discourages naive sequential planning and pushes the agent to separate work into parallel branches whereas nonetheless sustaining consistency.
One instance by the Kimi crew is a analysis workflow the place the system wants to find many area of interest creators. The orchestrator makes use of Agent Swarm to spawn numerous researcher brokers. Every agent explores completely different areas of the net, and the system merges outcomes right into a structured desk.
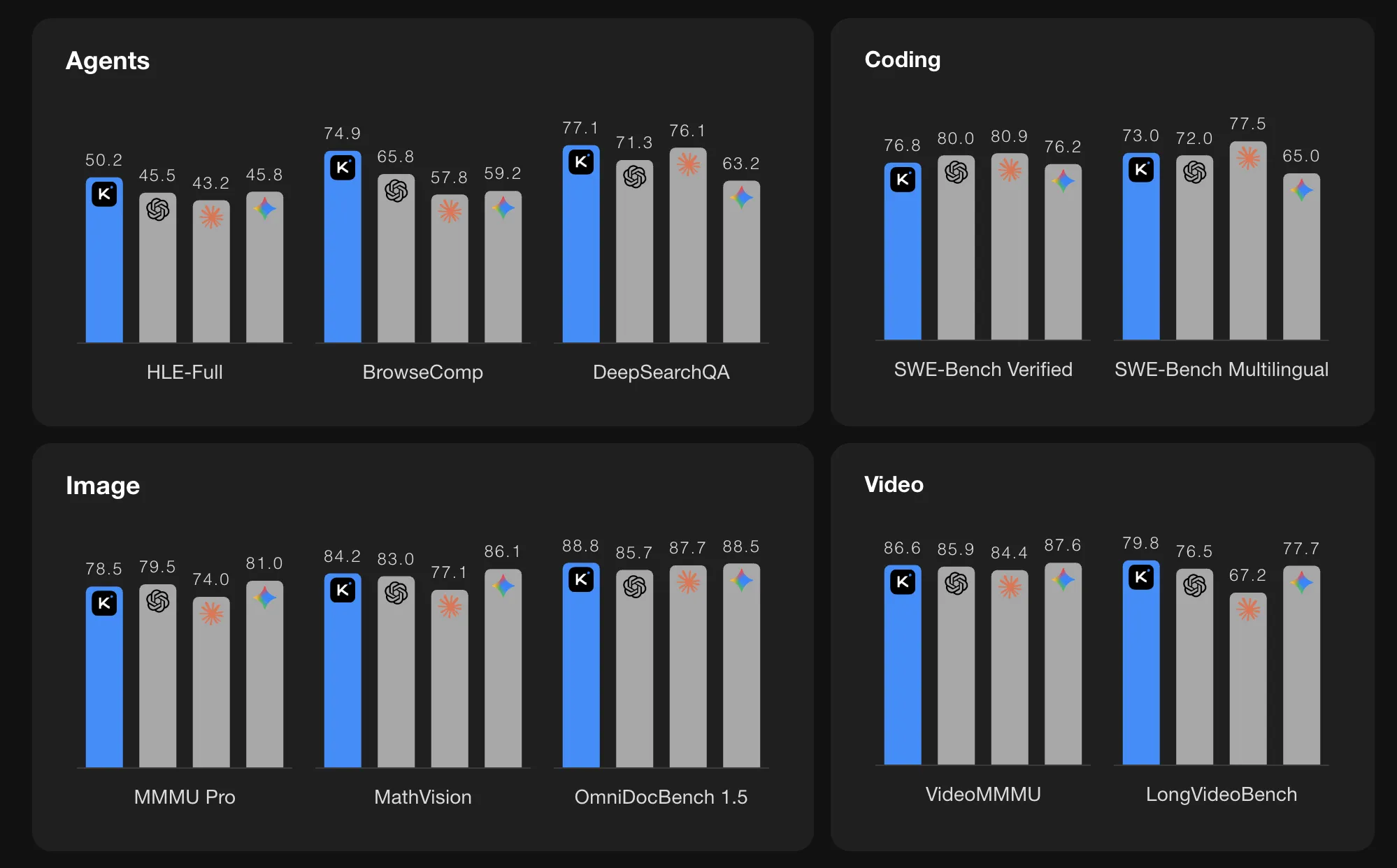
Benchmark Efficiency
On agentic benchmarks, Kimi K2.5 stories robust numbers. On HLE Full with instruments the rating is 50.2. On BrowseComp with context administration the rating is 74.9. In Agent Swarm mode the BrowseComp rating will increase additional to 78.4 and WideSearch metrics additionally enhance. The Kimi crew compares these values with GPT 5.2, Claude 4.5, Gemini 3 Professional, and DeepSeek V3, and K2.5 reveals the very best scores among the many listed fashions on these particular agentic suites.
On imaginative and prescient and video benchmarks K2.5 additionally stories excessive scores. MMMU Professional is 78.5 and VideoMMMU is 86.6. The mannequin performs nicely on OmniDocBench, OCRBench, WorldVQA, and different doc and scene understanding duties. These outcomes point out that the MoonViT encoder and lengthy context coaching are efficient for actual world multimodal issues, akin to studying complicated paperwork and reasoning over movies.

For coding benchmarks it lists SWE Bench Verified at 76.8, SWE Bench Professional at 50.7, SWE Bench Multilingual at 73.0, Terminal Bench 2.0 at 50.8, and LiveCodeBench v6 at 85.0. These numbers place K2.5 among the many strongest open supply coding fashions at the moment reported on these duties.
On lengthy context language benchmarks, K2.5 reaches 61.0 on LongBench V2 and 70.0 on AA LCR underneath customary analysis settings. For reasoning benchmarks it achieves excessive scores on AIME 2025, HMMT 2025 February, GPQA Diamond, and MMLU Professional when utilized in pondering mode.
Key Takeaways
- Combination of Consultants at trillion scale: Kimi K2.5 makes use of a Combination of Consultants structure with 1T whole parameters and about 32B lively parameters per token, 61 layers, 384 specialists, and 256K context size, optimized for lengthy multimodal and gear heavy workflows.
- Native multimodal coaching with MoonViT: The mannequin integrates a MoonViT imaginative and prescient encoder of about 400M parameters and is educated on about 15T blended imaginative and prescient and textual content tokens, so photos, paperwork, and language are dealt with in a single unified spine.
- Parallel Agent Swarm with PARL: Agent Swarm, educated with Parallel Agent Reinforcement Studying, can coordinate as much as 100 sub brokers and about 1,500 instrument calls per job, giving round 4.5 instances sooner execution versus a single agent on broad analysis duties.
- Robust benchmark ends in coding, imaginative and prescient, and brokers: K2.5 stories 76.8 on SWE Bench Verified, 78.5 on MMMU Professional, 86.6 on VideoMMMU, 50.2 on HLE Full with instruments, and 74.9 on BrowseComp, matching or exceeding listed closed fashions on a number of agentic and multimodal suites.
Try the Technical particulars and Mannequin Weight. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as nicely.

