
: A Software program Engineering Agent that may Function at Giant-Scale Codebases")
How far can a mid sized language mannequin go if the actual innovation strikes from the spine into the agent scaffold and gear stack? Meta and Harvard researchers have launched the Confucius Code Agent, an open sourced AI software program engineer constructed on the Confucius SDK that’s designed for industrial scale software program repositories and lengthy operating classes. The system targets actual GitHub tasks, advanced check toolchains at analysis time, and reproducible outcomes on benchmarks comparable to SWE Bench Professional and SWE Bench Verified, whereas exposing the total scaffold for builders.
Confucius SDK, scaffolding across the mannequin
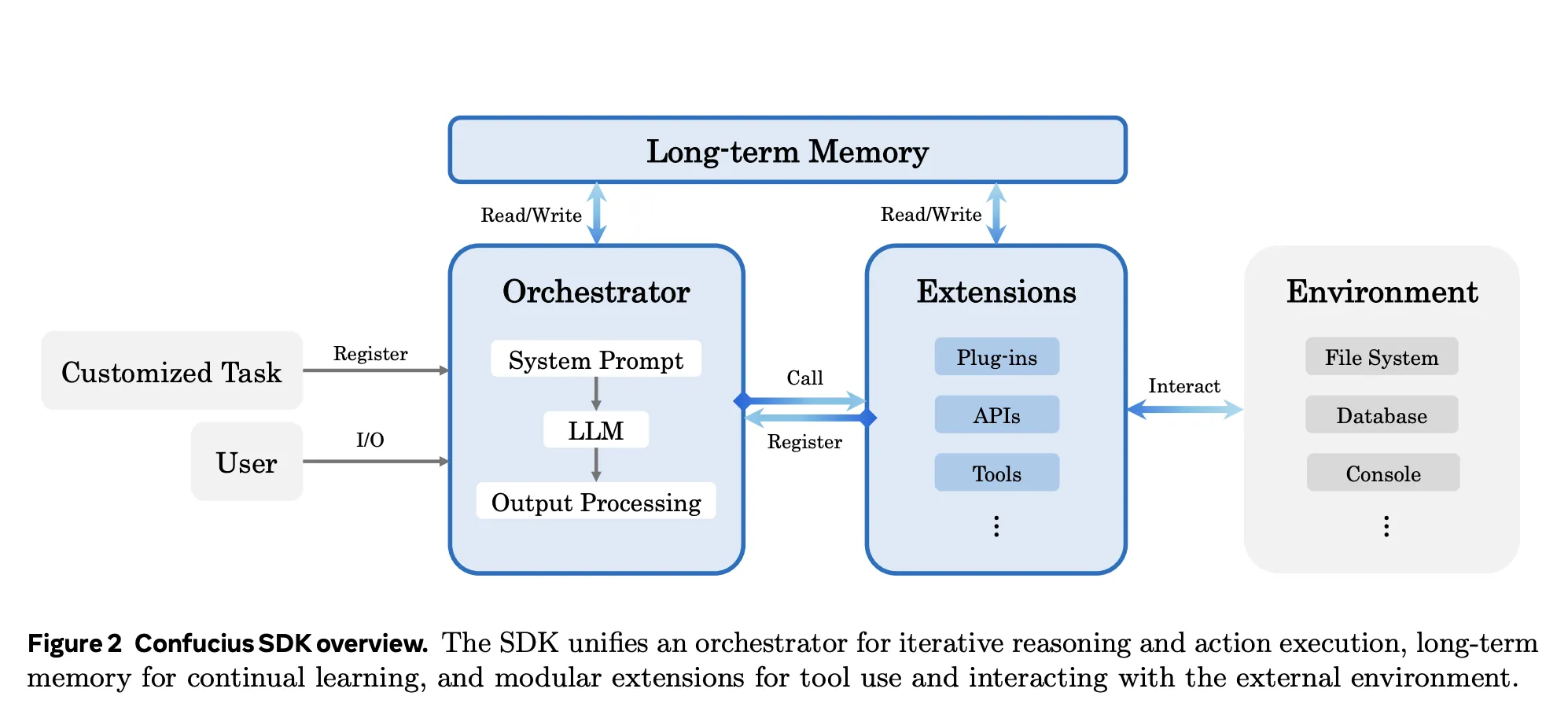
The Confucius SDK is an agent growth platform that treats scaffolding as a main design downside reasonably than a skinny wrapper round a language mannequin. It’s organized round 3 axes, Agent Expertise, Consumer Expertise, and Developer Expertise.
Agent Expertise controls what the mannequin sees, together with context structure, working reminiscence and gear outcomes. Consumer Expertise focuses on readable traces, code diffs and safeguards for human engineers. Developer Expertise focuses on observability, configuration and debugging of the agent itself.
The SDK introduces 3 core mechanisms, a unified orchestrator with hierarchical working reminiscence, a persistent word taking system, and a modular extension interface for instruments. A meta agent then automates synthesis and refinement of agent configurations by means of a construct, check, enhance loop. The Confucius Code Agent is one concrete instantiation of this scaffold for software program engineering.
Hierarchical working reminiscence for lengthy horizon coding
Actual software program duties on SWE Bench Professional usually require reasoning over dozens of information and lots of interplay steps. The orchestrator in Confucius SDK maintains hierarchical working reminiscence, which partitions a trajectory into scopes, summarizes previous steps and retains compressed context for later turns.
This design helps preserve prompts inside mannequin context limits whereas preserving essential artifacts comparable to patches, error logs and design selections. The important thing level is that efficient software primarily based coding brokers want an express reminiscence structure, not only a sliding window of earlier messages.
Persistent word taking for cross session studying
The second mechanism is a word taking system that makes use of a devoted agent to jot down structured Markdown notes from execution traces. These notes seize process particular methods, repository conventions and customary failure modes, and they’re saved as long run reminiscence that may be reused throughout classes.
The analysis group ran Confucius Code Agent twice on 151 SWE Bench Professional cases with Claude 4.5 Sonnet. On the primary run the agent solves duties from scratch and generates notes. On the second run the agent reads these notes. On this setting, common turns drop from 64 to 61, token utilization drops from about 104k to 93k, and Resolve@1 improves from 53.0 to 54.4. This reveals that notes should not simply logs, they perform as efficient cross session reminiscence.
Modular extensions and gear use sophistication
Confucius SDK exposes instruments as extensions, for instance file modifying, command execution, check runners and code search. Every extension can preserve its personal state and immediate wiring.
The analysis group research the influence of software use sophistication utilizing an ablation on a 100 instance subset of SWE Bench Professional. With Claude 4 Sonnet, transferring from a configuration with out superior context options to at least one with superior context raises Resolve@1 from 42.0 to 48.6. With Claude 4.5 Sonnet, a easy software use configuration reaches 44.0, whereas richer software dealing with reaches 51.6, with 51.0 for an intermediate variant. These numbers point out that how the agent chooses and sequences instruments issues nearly as a lot because the spine mannequin selection.
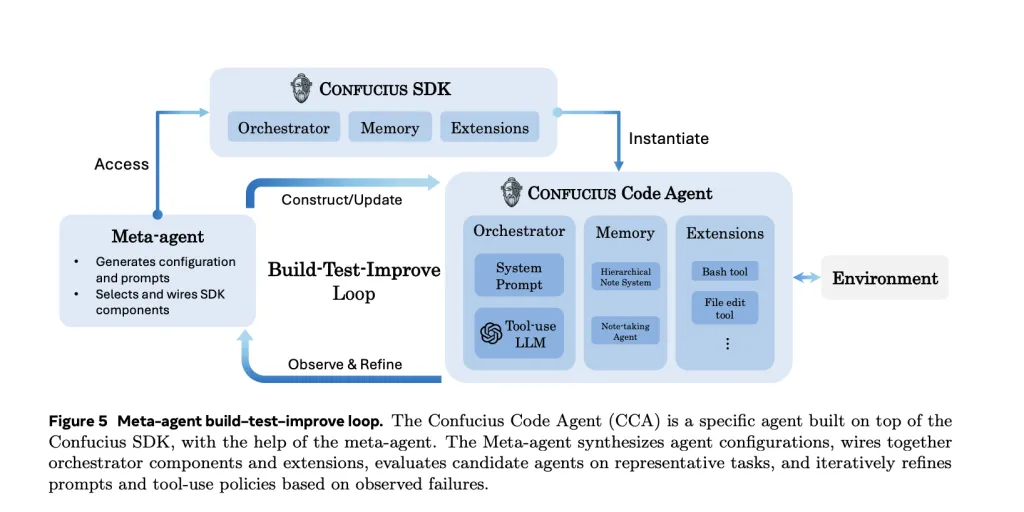
Meta agent for automated agent design
On prime of those mechanisms, the Confucius SDK features a meta agent that takes a pure language specification of an agent and iteratively proposes configurations, prompts and extension units. It then runs the candidate agent on duties, inspects traces and metrics, and edits the configuration in a construct, check, enhance loop.
The Confucius Code Agent that the analysis group evaluates is produced with the assistance of this meta agent, reasonably than solely hand tuned. This strategy turns a few of the agent engineering course of itself into an LLM guided optimization downside.
Outcomes on SWE Bench Professional and SWE Bench Verified
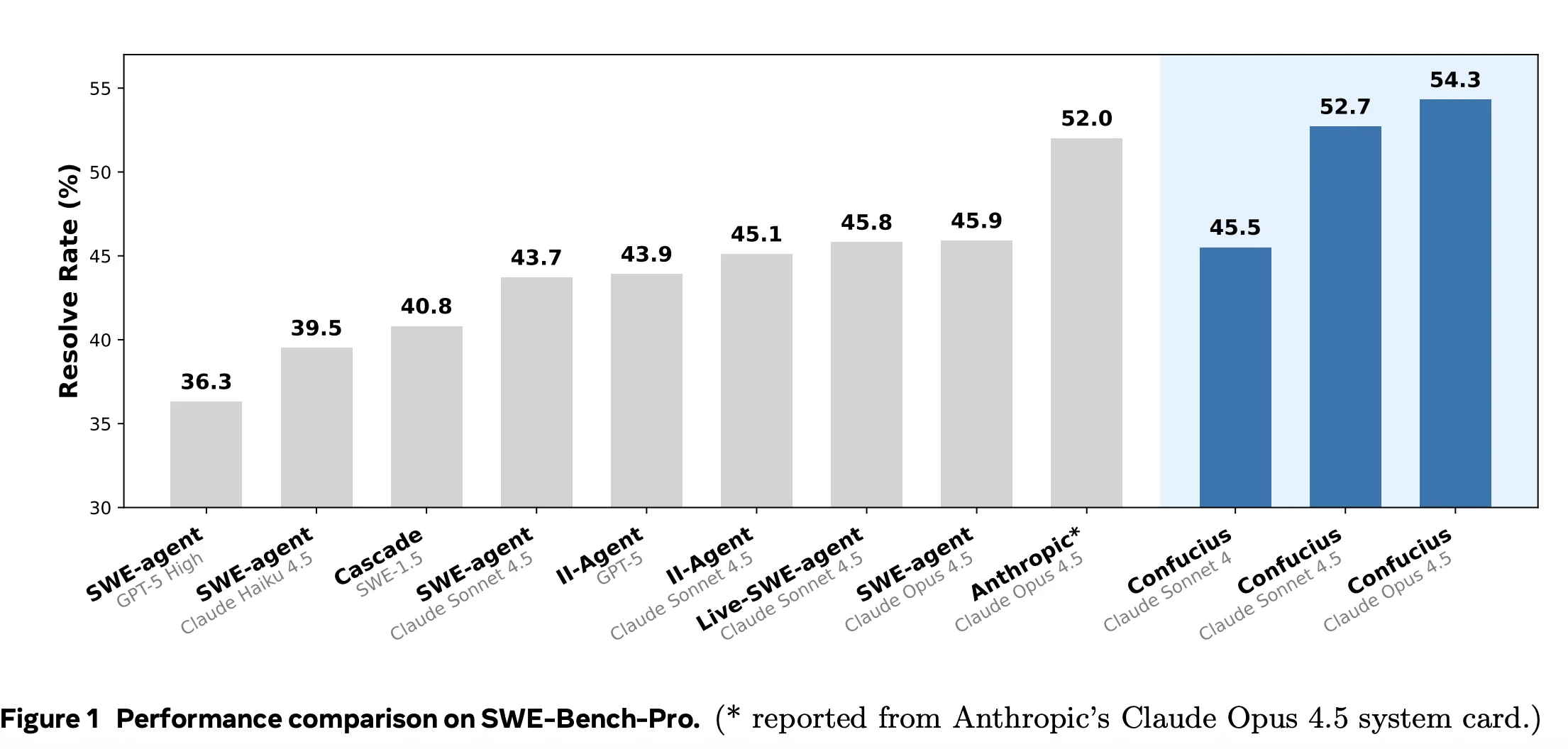
The primary analysis makes use of SWE Bench Professional, which has 731 GitHub points that require modifying actual repositories till assessments move. All in contrast methods share the identical repositories, software setting and analysis harness, so variations come from the scaffolds and fashions.
On SWE Bench Professional, the reported Resolve@1 scores are
- Claude 4 Sonnet with SWE Agent, 42.7
- Claude 4 Sonnet with Confucius Code Agent, 45.5
- Claude 4.5 Sonnet with SWE Agent, 43.6
- Claude 4.5 Sonnet with Reside SWE Agent, 45.8
- Claude 4.5 Sonnet with Confucius Code Agent, 52.7
- Claude 4.5 Opus with Anthropic system card scaffold, 52.0
- Claude 4.5 Opus with Confucius Code Agent, 54.3
These outcomes present {that a} robust scaffold with a mid tier mannequin, Claude 4.5 Sonnet with Confucius Code Agent at 52.7, can outperform a stronger mannequin with a weaker scaffold, Claude 4.5 Opus with 52.0.
On SWE Bench Verified, Confucius Code Agent with Claude 4 Sonnet reaches Resolve@1 74.6, in comparison with 66.6 for SWE Agent and 72.8 for OpenHands. A mini SWE Agent variant with Claude 4.5 Sonnet reaches 70.6, which can be beneath Confucius Code Agent with Claude 4 Sonnet.
The analysis group additionally report efficiency as a perform of edited file depend. For duties modifying 1 to 2 information, Confucius Code Agent reaches 57.8 Resolve@1, for 3 to 4 information it reaches 49.2, for five to six information it reaches 44.1, for 7 to 10 information it reaches 52.6, and for greater than 10 information it reaches 44.4. This means secure habits on multi file modifications in massive codebases.
Key Takeaways
- Scaffolding can outweigh mannequin measurement: Confucius Code Agent reveals that with robust scaffolding, Claude 4.5 Sonnet reaches 52.7 Resolve@1 on SWE-Bench-Professional, surpassing Claude 4.5 Opus with a weaker scaffold at 52.0.
- Hierarchical working reminiscence is crucial for lengthy horizon coding: The Confucius SDK orchestrator makes use of hierarchical working reminiscence and context compression to handle lengthy trajectories over massive repositories, reasonably than counting on a easy rolling historical past.
- Persistent notes act as efficient cross session reminiscence: On 151 SWE-Bench-Professional duties with Claude 4.5 Sonnet, reusing structured notes reduces turns from 64 to 61, token utilization from about 104k to 93k, and will increase Resolve@1 from 53.0 to 54.4.
- Software configuration materially impacts success charges: On a 100 process SWE-Bench-Professional subset, transferring from easy to richer software dealing with with Claude 4.5 Sonnet will increase Resolve@1 from 44.0 to 51.6, indicating that discovered software routing and restoration methods are a significant efficiency lever, not simply an implementation element.
- Meta agent automates agent design and tuning: A meta agent iteratively proposes prompts, software units and configurations, then evaluates and edits them in a construct, check, enhance loop, and the manufacturing Confucius Code Agent is itself generated with this course of reasonably than solely guide tuning.
Try the PAPER HERE. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be part of us on telegram as nicely.
Try our newest launch of ai2025.dev, a 2025-focused analytics platform that turns mannequin launches, benchmarks, and ecosystem exercise right into a structured dataset you may filter, evaluate, and export.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

