
 Structure and Circulate Matching")
Tencent Hunyuan’s 3D Digital Human staff has launched HY-Movement 1.0, an open weight text-to-3D human movement era household that scales Diffusion Transformer based mostly Circulate Matching to 1B parameters within the movement area. The fashions flip pure language prompts plus an anticipated length into 3D human movement clips on a unified SMPL-H skeleton and can be found on GitHub and Hugging Face with code, checkpoints and a Gradio interface for native use.
What HY-Movement 1.0 supplies for builders?
HY-Movement 1.0 is a collection of text-to-3D human movement era fashions constructed on a Diffusion Transformer, DiT, educated with a Circulate Matching goal. The mannequin collection showcases 2 variants, HY-Movement-1.0 with 1.0B parameters as the usual mannequin and HY-Movement-1.0-Lite with 0.46B parameters as a light-weight possibility.
Each fashions generate skeleton based mostly 3D character animations from easy textual content prompts. The output is a movement sequence on an SMPL-H skeleton that may be built-in into 3D animation or sport pipelines, for instance for digital people, cinematics and interactive characters. The discharge contains inference scripts, a batch oriented CLI and a Gradio net app, and helps macOS, Home windows and Linux.
Information engine and taxonomy
The coaching knowledge comes from 3 sources, within the wild human movement movies, movement seize knowledge and 3D animation belongings for sport manufacturing. The analysis staff begins from 12M top quality video clips from HunyuanVideo, runs shot boundary detection to separate scenes and a human detector to maintain clips with individuals, then applies the GVHMR algorithm to reconstruct SMPL X movement tracks. Movement seize periods and 3D animation libraries contribute about 500 hours of extra movement sequences.
All knowledge is retargeted onto a unified SMPL-H skeleton by way of mesh becoming and retargeting instruments. A multi stage filter removes duplicate clips, irregular poses, outliers in joint velocity, anomalous displacements, lengthy static segments and artifacts resembling foot sliding. Motions are then canonicalized, resampled to 30 fps and segmented into clips shorter than 12 seconds with a set world body, Y axis up and the character going through the optimistic Z axis. The ultimate corpus incorporates over 3,000 hours of movement, of which 400 hours are top quality 3D movement with verified captions.
On high of this, the analysis staff defines a 3 degree taxonomy. On the high degree there are 6 courses, Locomotion, Sports activities and Athletics, Health and Out of doors Actions, Each day Actions, Social Interactions and Leisure and Sport Character Actions. These broaden into greater than 200 nice grained movement classes on the leaves, which cowl each easy atomic actions and concurrent or sequential movement combos.
Movement illustration and HY-Movement DiT
HY-Movement 1.0 makes use of the SMPL-H skeleton with 22 physique joints with out palms. Every body is a 201 dimensional vector that concatenates international root translation in 3D area, international physique orientation in a steady 6D rotation illustration, 21 native joint rotations in 6D type and 22 native joint positions in 3D coordinates. Velocities and foot contact labels are eliminated as a result of they slowed coaching and didn’t assist ultimate high quality. This illustration is suitable with animation workflows and near the DART mannequin illustration.
The core community is a hybrid HY Movement DiT. It first applies twin stream blocks that course of movement latents and textual content tokens individually. In these blocks, every modality has its personal QKV projections and MLP, and a joint consideration module permits movement tokens to question semantic options from textual content tokens whereas maintaining modality particular construction. The community then switches to single stream blocks that concatenate movement and textual content tokens into one sequence and course of them with parallel spatial and channel consideration modules to carry out deeper multimodal fusion.
For textual content conditioning, the system makes use of a twin encoder scheme. Qwen3 8B supplies token degree embeddings, whereas a CLIP-L mannequin supplies international textual content options. A Bidirectional Token Refiner fixes the causal consideration bias of the LLM for non autoregressive era. These alerts feed the DiT by way of adaptive layer normalization conditioning. Consideration is uneven, movement tokens can attend to all textual content tokens, however textual content tokens don’t attend again to movement, which prevents noisy movement states from corrupting the language illustration. Temporal consideration contained in the movement department makes use of a slim sliding window of 121 frames, which focuses capability on native kinematics whereas maintaining price manageable for lengthy clips. Full Rotary Place Embedding is utilized after concatenating textual content and movement tokens to encode relative positions throughout the entire sequence.
Circulate Matching, immediate rewriting and coaching
HY-Movement 1.0 makes use of Circulate Matching as a substitute of ordinary denoising diffusion. The mannequin learns a velocity discipline alongside a steady path that interpolates between Gaussian noise and actual movement knowledge. Throughout coaching, the target is a imply squared error between predicted and floor fact velocities alongside this path. Throughout inference, the discovered bizarre differential equation is built-in from noise to a clear trajectory, which provides steady coaching for lengthy sequences and suits the DiT structure.
A separate Period Prediction and Immediate Rewrite module improves instruction following. It makes use of Qwen3 30B A3B as the bottom mannequin and is educated on artificial consumer model prompts generated from movement captions with a VLM and LLM pipeline, for instance Gemini 2.5 Professional. This module predicts an appropriate movement length and rewrites casual prompts into normalized textual content that’s simpler for the DiT to comply with. It’s educated first with supervised nice tuning after which refined with Group Relative Coverage Optimization, utilizing Qwen3 235B A22B as a reward mannequin that scores semantic consistency and length plausibility.
Coaching follows a 3 stage curriculum. Stage 1 performs massive scale pretraining on the complete 3,000 hour dataset to study a broad movement prior and fundamental textual content movement alignment. Stage 2 nice tunes on the 400 hour top quality set to sharpen movement element and enhance semantic correctness with a smaller studying price. Stage 3 applies reinforcement studying, first Direct Desire Optimization utilizing 9,228 curated human desire pairs sampled from about 40,000 generated pairs, then Circulate GRPO with a composite reward. The reward combines a semantic rating from a Textual content Movement Retrieval mannequin and a physics rating that penalizes artifacts like foot sliding and root drift, below a KL regularization time period to remain near the supervised mannequin.
Benchmarks, scaling habits and limitations
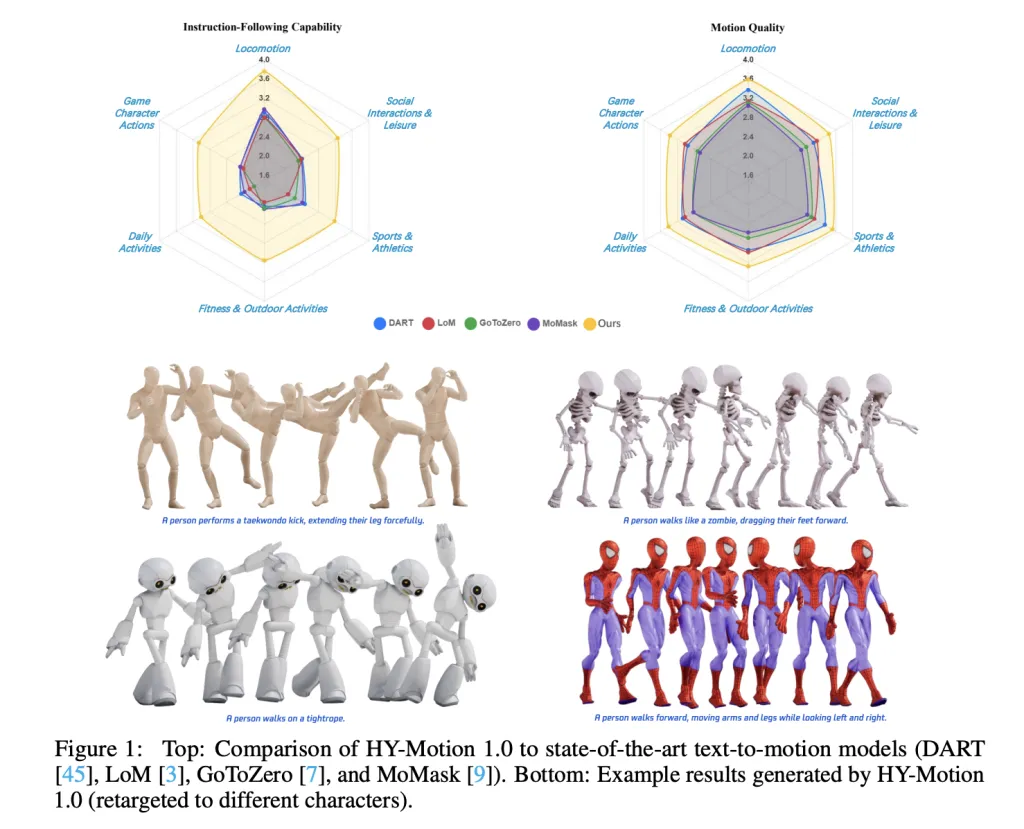
For analysis, the staff builds a take a look at set of over 2,000 prompts that span the 6 taxonomy classes and embrace easy, concurrent and sequential actions. Human raters rating instruction following and movement high quality on a scale from 1 to five. HY-Movement 1.0 reaches a median instruction following rating of three.24 and an SSAE rating of 78.6 %. Baseline text-to-motion methods resembling DART, LoM, GoToZero and MoMask obtain scores between 2.17 and a pair of.31 with SSAE between 42.7 % and 58.0 %. For movement high quality, HY-Movement 1.0 reaches 3.43 on common versus 3.11 for the most effective baseline.
Scaling experiments research DiT fashions with 0.05B, 0.46B, 0.46B educated solely on 400 hours and 1B parameters. Instruction following improves steadily with mannequin measurement, with the 1B mannequin reaching a median of three.34. Movement high quality saturates across the 0.46B scale, the place the 0.46B and 1B fashions attain comparable averages between 3.26 and three.34. Comparability of the 0.46B mannequin educated on 3,000 hours and the 0.46B mannequin educated solely on 400 hours reveals that bigger knowledge quantity is essential for instruction alignment, whereas top quality curation primarily improves realism.
Key Takeaways
- Billion scale DiT Circulate Matching for movement: HY-Movement 1.0 is the primary Diffusion Transformer based mostly Circulate Matching mannequin scaled to the 1B parameter degree particularly for textual content to 3D human movement, concentrating on excessive constancy instruction following throughout numerous actions.
- Giant scale, curated movement corpus: The mannequin is pretrained on over 3,000 hours of reconstructed, mocap and animation movement knowledge and nice tuned on a 400 hour top quality subset, all retargeted to a unified SMPL H skeleton and arranged into greater than 200 movement classes.
- Hybrid DiT structure with robust textual content conditioning: HY-Movement 1.0 makes use of a hybrid twin stream and single stream DiT with uneven consideration, slim band temporal consideration and twin textual content encoders, Qwen3 8B and CLIP L, to fuse token degree and international semantics into movement trajectories.
- RL aligned immediate rewrite and coaching pipeline: A devoted Qwen3 30B based mostly module predicts movement length and rewrites consumer prompts, and the DiT is additional aligned with Direct Desire Optimization and Circulate GRPO utilizing semantic and physics rewards, which improves realism and instruction following past supervised coaching.
Try the Paper and Full Codes right here. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

