
As AI migrates from the cloud to the Edge, we see the expertise being utilized in an ever-expanding number of use instances – starting from anomaly detection to functions together with sensible purchasing, surveillance, robotics, and manufacturing unit automation. Therefore, there isn’t any one-size-fits-all answer. However with the speedy development of camera-enabled units, AI has been most generally adopted for analyzing real-time video knowledge to automate video monitoring to reinforce security, enhance operational efficiencies, and supply higher buyer experiences, finally gaining a aggressive edge of their industries. To higher assist video evaluation, it’s essential to perceive the methods for optimizing system efficiency in edge AI deployments.
- Choosing the right-sized compute engines to satisfy or exceed the required efficiency ranges. For an AI software, these compute engines should carry out the features of all the imaginative and prescient pipeline (i.e., video pre- and post-processing, neural community inferencing).
A devoted AI accelerator, whether or not it’s discrete or built-in into an SoC (versus operating the AI inferencing on a CPU or GPU) could also be required.
- Comprehending the distinction between throughput and latency; whereby throughput is the speed that knowledge might be processed in a system and latency measures the info processing delay via the system and is usually related to real-time responsiveness. For instance, a system can generate picture knowledge at 100 frames per second (throughput) however it takes 100ms (latency) for a picture to undergo the system.
- Contemplating the power to simply scale AI efficiency sooner or later to accommodate rising wants, altering necessities, and evolving applied sciences (e.g., extra superior AI fashions for elevated performance and accuracy). You may accomplish efficiency scaling utilizing AI accelerators in module format or with further AI accelerator chips.
The precise efficiency necessities are software dependent. Usually, one can count on that for video analytics, the system should course of knowledge streams coming in from cameras at 30-60 frames per second and with a decision of 1080p or 4k. An AI-enabled digicam would course of a single stream; an edge equipment would course of a number of streams in parallel. In both case, the sting AI system should assist the pre-processing features to remodel the digicam’s sensor knowledge right into a format that matches the enter necessities of the AI inferencing part (Determine 1).
Pre-processing features take within the uncooked knowledge and carry out duties reminiscent of resize, normalization, and shade house conversion, earlier than feeding the enter into the mannequin operating on the AI accelerator. Pre-processing can use environment friendly picture processing libraries like OpenCV to scale back the preprocessing instances. Postprocessing entails analyzing the output of the inference. It makes use of duties reminiscent of non-maximum suppression (NMS interprets the output of most object detection fashions) and picture show to generate actionable insights, reminiscent of bounding bins, class labels, or confidence scores.
Determine 1. For AI mannequin inferencing, the pre- and post-processing features are sometimes carried out on an functions processor.
The AI mannequin inferencing can have the extra problem of processing a number of neural community fashions per body, relying on the appliance’s capabilities. Laptop imaginative and prescient functions normally contain a number of AI duties requiring a pipeline of a number of fashions. Moreover, one mannequin’s output is usually the subsequent mannequin’s enter. In different phrases, fashions in an software typically rely on one another and should be executed sequentially. The precise set of fashions to execute will not be static and will range dynamically, even on a frame-by-frame foundation.
The problem of operating a number of fashions dynamically requires an exterior AI accelerator with devoted and sufficiently giant reminiscence to retailer the fashions. Usually the built-in AI accelerator inside an SoC is unable to handle the multi-model workload because of constraints imposed by shared reminiscence subsystem and different sources within the SoC.
For instance, movement prediction-based object monitoring depends on steady detections to find out a vector which is used to establish the tracked object at a future place. The effectiveness of this strategy is proscribed as a result of it lacks true reidentification functionality. With movement prediction, an object’s observe might be misplaced because of missed detections, occlusions, or the item leaving the sphere of view, even momentarily. As soon as misplaced, there isn’t any technique to re-associate the item’s observe. Including reidentification solves this limitation however requires a visible look embedding (i.e., a picture fingerprint). Look embeddings require a second community to generate a function vector by processing the picture contained contained in the bounding field of the item detected by the primary community. This embedding can be utilized to reidentify the item once more, regardless of time or house. Since embeddings should be generated for every object detected within the area of view, processing necessities enhance because the scene turns into busier. Object monitoring with reidentification requires cautious consideration between performing high-accuracy / excessive decision / high-frame charge detection and reserving adequate overhead for embeddings scalability. One technique to remedy the processing requirement is to make use of a devoted AI accelerator. As talked about earlier, the SoC’s AI engine can endure from the shortage of shared reminiscence sources. Mannequin optimization can be used to decrease the processing requirement, however it may impression efficiency and/or accuracy.
In a sensible digicam or edge equipment, the built-in SoC (i.e., host processor) acquires the video frames and performs the pre-processing steps we described earlier. These features might be carried out with the SoC’s CPU cores or GPU (if one is offered), however they can be carried out by devoted {hardware} accelerators within the SoC (e.g., picture sign processor). After these pre-processing steps are accomplished, the AI accelerator that’s built-in into the SoC can then instantly entry this quantized enter from system reminiscence, or within the case of a discrete AI accelerator, the enter is then delivered for inference, sometimes over the USB or PCIe interface.
An built-in SoC can comprise a spread of computation items, together with CPUs, GPUs, AI accelerator, imaginative and prescient processors, video encoders/decoders, picture sign processor (ISP), and extra. These computation items all share the identical reminiscence bus and consequently entry to the identical reminiscence. Moreover, the CPU and GPU may additionally need to play a task within the inference and these items shall be busy operating different duties in a deployed system. That is what we imply by system-level overhead (Determine 2).
Many builders mistakenly consider the efficiency of the built-in AI accelerator within the SoC with out contemplating the impact of system-level overhead on complete efficiency. For instance, take into account operating a YOLO benchmark on a 50 TOPS AI accelerator built-in in an SoC, which mightobtain a benchmark results of 100 inferences/second (IPS). However in a deployed system with all its different computational items energetic, these 50 TOPS may cut back to one thing like 12 TOPS and the general efficiency would solely yield 25 IPS, assuming a beneficiant 25% utilization issue. System overhead is at all times an element if the platform is constantly processing video streams. Alternatively, with a discrete AI accelerator (e.g., Kinara Ara-1, Hailo-8, Intel Myriad X), the system-level utilization could possibly be better than 90% as a result of as soon as the host SoC initiates the inferencing operate and transfers the AI mannequin’s enter knowledge, the accelerator runs autonomously using its devoted reminiscence for accessing mannequin weights and parameters.
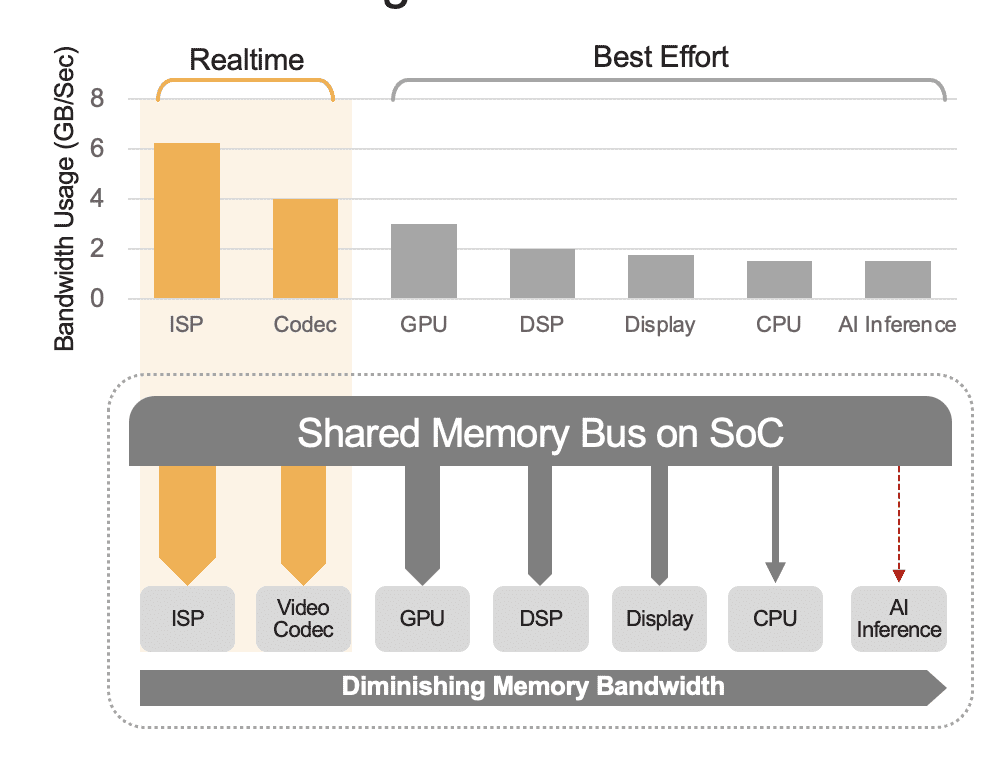
Determine 2. The shared reminiscence bus will govern the system-level efficiency, proven right here with estimated values. Actual values will range based mostly in your software utilization mannequin and the SoC’s compute unit configuration.
Till this level, we’ve mentioned AI efficiency by way of frames per second and TOPS. However low latency is one other vital requirement to ship a system’s real-time responsiveness. For instance, in gaming, low latency is essential for a seamless and responsive gaming expertise, significantly in motion-controlled video games and digital actuality (VR) methods. In autonomous driving methods, low latency is significant for real-time object detection, pedestrian recognition, lane detection, and site visitors signal recognition to keep away from compromising security. Autonomous driving methods sometimes require end-to-end latency of lower than 150ms from detection to the precise motion. Equally, in manufacturing, low latency is crucial for real-time defect detection, anomaly recognition, and robotic steering rely on low-latency video analytics to make sure environment friendly operation and decrease manufacturing downtime.
Normally, there are three parts of latency in a video analytics software (Determine 3):
- Information seize latency is the time from the digicam sensor capturing a video body to the body’s availability to the analytics system for processing. You may optimize this latency by selecting a digicam with a quick sensor and low latency processor, choosing optimum body charges, and utilizing environment friendly video compression codecs.
- Information switch latency is the time for captured and compressed video knowledge to journey from the digicam to the sting units or native servers. This contains community processing delays that happen at every finish level.
- Information processing latency refers back to the time for the sting units to carry out video processing duties reminiscent of body decompression and analytics algorithms (e.g., movement prediction-based object monitoring, face recognition). As identified earlier, processing latency is much more vital for functions that should run a number of AI fashions for every video body.
Determine 3. The video analytics pipeline consists of knowledge seize, knowledge switch and knowledge processing.
The info processing latency might be optimized utilizing an AI accelerator with an structure designed to reduce knowledge motion throughout the chip and between compute and varied ranges of the reminiscence hierarchy. Additionally, to enhance the latency and system-level effectivity, the structure should assist zero (or close to zero) switching time between fashions, to raised assist the multi-model functions we mentioned earlier. One other issue for each improved efficiency and latency pertains to algorithmic flexibility. In different phrases, some architectures are designed for optimum habits solely on particular AI fashions, however with the quickly altering AI surroundings, new fashions for greater efficiency and higher accuracy are showing in what looks like each different day. Subsequently, choose an edge AI processor with no sensible restrictions on mannequin topology, operators, and dimension.
There are various elements to be thought of in maximizing efficiency in an edge AI equipment together with efficiency and latency necessities and system overhead. A profitable technique ought to take into account an exterior AI accelerator to beat the reminiscence and efficiency limitations within the SoC’s AI engine.
C.H. Chee is an completed product advertising and administration government, Chee has in depth expertise in selling merchandise and options within the semiconductor trade, specializing in vision-based AI, connectivity and video interfaces for a number of markets together with enterprise and client. As an entrepreneur, Chee co-founded two video semiconductor start-ups that had been acquired by a public semiconductor firm. Chee led product advertising groups and enjoys working with a small group that focuses on reaching nice outcomes.

