

Query:
You’re deploying an LLM in manufacturing. Producing the primary few tokens is quick, however because the sequence grows, every extra token takes progressively longer to generate—regardless that the mannequin structure and {hardware} stay the identical.
If compute isn’t the first bottleneck, what inefficiency is inflicting this slowdown, and the way would you redesign the inference course of to make token era considerably quicker?
What’s KV Caching and the way does it make token era quicker?
KV caching is an optimization approach used throughout textual content era in giant language fashions to keep away from redundant computation. In autoregressive era, the mannequin produces textual content one token at a time, and at every step it usually recomputes consideration over all earlier tokens. Nevertheless, the keys (Ok) and values (V) computed for earlier tokens by no means change.
With KV caching, the mannequin shops these keys and values the primary time they’re computed. When producing the following token, it reuses the cached Ok and V as an alternative of recomputing them from scratch, and solely computes the question (Q), key, and worth for the brand new token. Consideration is then calculated utilizing the cached info plus the brand new token.
This reuse of previous computations considerably reduces redundant work, making inference quicker and extra environment friendly—particularly for lengthy sequences—at the price of extra reminiscence to retailer the cache. Take a look at the Follow Pocket book right here

Evaluating the Impression of KV Caching on Inference Velocity
On this code, we benchmark the influence of KV caching throughout autoregressive textual content era. We run the identical immediate by means of the mannequin a number of occasions, as soon as with KV caching enabled and as soon as with out it, and measure the common era time. By holding the mannequin, immediate, and era size fixed, this experiment isolates how reusing cached keys and values considerably reduces redundant consideration computation and hurries up inference. Take a look at the Follow Pocket book right here
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
machine = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(model_name)
mannequin = AutoModelForCausalLM.from_pretrained(model_name).to(machine)
immediate = "Clarify KV caching in transformers."
inputs = tokenizer(immediate, return_tensors="pt").to(machine)
for use_cache in (True, False):
occasions = []
for _ in vary(5):
begin = time.time()
mannequin.generate(
**inputs,
use_cache=use_cache,
max_new_tokens=1000
)
occasions.append(time.time() - begin)
print(
f"{'with' if use_cache else 'with out'} KV caching: "
f"{spherical(np.imply(occasions), 3)} ± {spherical(np.std(occasions), 3)} seconds"
)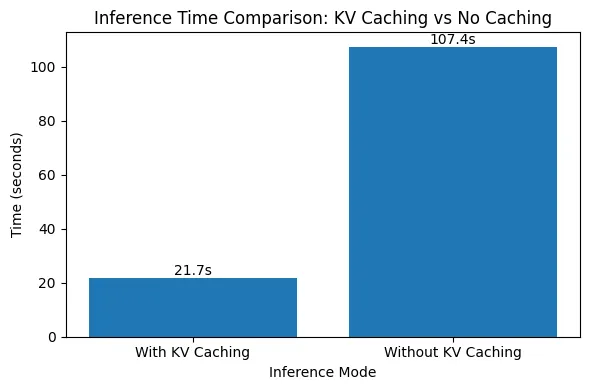
The outcomes clearly reveal the influence of KV caching on inference pace. With KV caching enabled, producing 1000 tokens takes round 21.7 seconds, whereas disabling KV caching will increase the era time to over 107 seconds—almost a 5× slowdown. This sharp distinction happens as a result of, with out KV caching, the mannequin recomputes consideration over all beforehand generated tokens at each step, resulting in quadratic progress in computation. Take a look at the Follow Pocket book right here
With KV caching, previous keys and values are reused, eliminating redundant work and holding era time almost linear because the sequence grows. This experiment highlights why KV caching is crucial for environment friendly, real-world deployment of autoregressive language fashions.
Take a look at the Follow Pocket book right here

I’m a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I’ve a eager curiosity in Knowledge Science, particularly Neural Networks and their utility in numerous areas.

