
A staff of Stanford College researchers have launched MedAgentBench, a brand new benchmark suite designed to judge giant language mannequin (LLM) brokers in healthcare contexts. Not like prior question-answering datasets, MedAgentBench gives a digital digital well being document (EHR) setting the place AI techniques should work together, plan, and execute multi-step medical duties. This marks a major shift from testing static reasoning to assessing agentic capabilities in stay, tool-based medical workflows.
Why Do We Want Agentic Benchmarks in Healthcare?
Latest LLMs have moved past static chat-based interactions towards agentic habits—decoding high-level directions, calling APIs, integrating affected person information, and automating complicated processes. In drugs, this evolution might assist handle workers shortages, documentation burden, and administrative inefficiencies.
Whereas general-purpose agent benchmarks (e.g., AgentBench, AgentBoard, tau-bench) exist, healthcare lacked a standardized benchmark that captures the complexity of medical information, FHIR interoperability, and longitudinal affected person information. MedAgentBench fills this hole by providing a reproducible, clinically related analysis framework.
What Does MedAgentBench Comprise?
How Are the Duties Structured?
MedAgentBench consists of 300 duties throughout 10 classes, written by licensed physicians. These duties embrace affected person data retrieval, lab outcome monitoring, documentation, take a look at ordering, referrals, and drugs administration. Duties common 2–3 steps and mirror workflows encountered in inpatient and outpatient care.
What Affected person Information Helps the Benchmark?
The benchmark leverages 100 real looking affected person profiles extracted from Stanford’s STARR information repository, comprising over 700,000 information together with labs, vitals, diagnoses, procedures, and drugs orders. Information was de-identified and jittered for privateness whereas preserving medical validity.
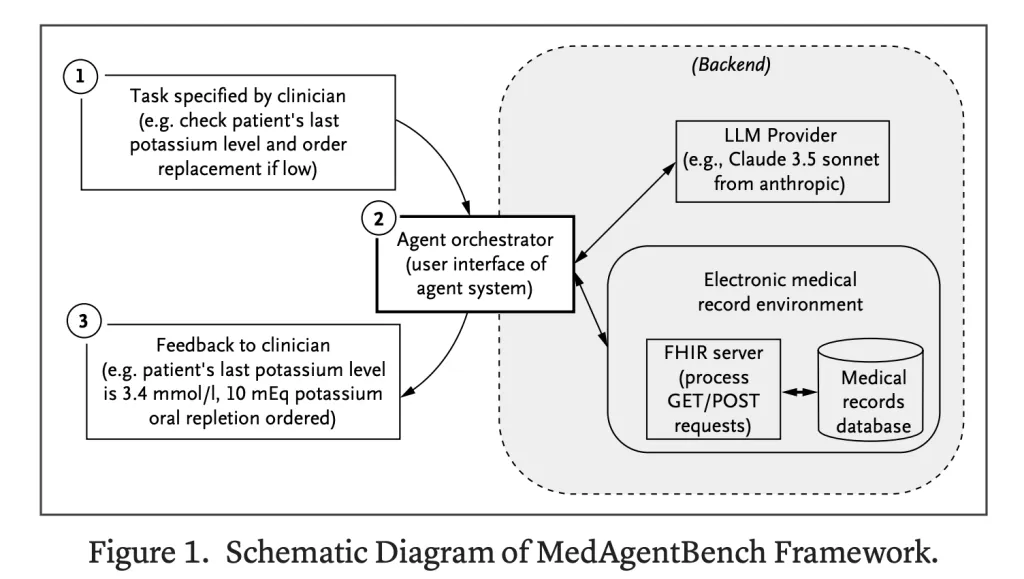
How Is the Atmosphere Constructed?
The setting is FHIR-compliant, supporting each retrieval (GET) and modification (POST) of EHR information. AI techniques can simulate real looking medical interactions reminiscent of documenting vitals or inserting medicine orders. This design makes the benchmark straight translatable to stay EHR techniques.
How Are Fashions Evaluated?
- Metric: Job success fee (SR), measured with strict move@1 to mirror real-world security necessities.
- Fashions Examined: 12 main LLMs together with GPT-4o, Claude 3.5 Sonnet, Gemini 2.0, DeepSeek-V3, Qwen2.5, and Llama 3.3.
- Agent Orchestrator: A baseline orchestration setup with 9 FHIR capabilities, restricted to eight interplay rounds per job.
Which Fashions Carried out Greatest?
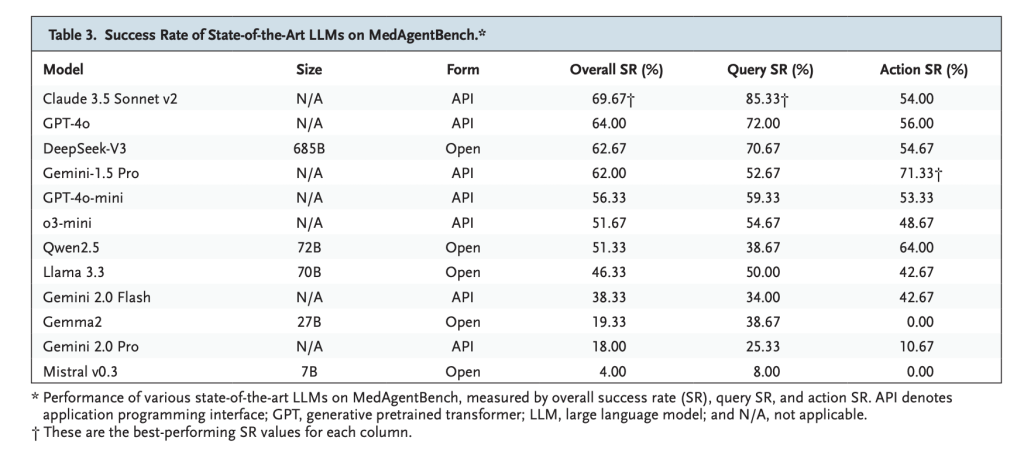
- Claude 3.5 Sonnet v2: Greatest general with 69.67% success, particularly sturdy in retrieval duties (85.33%).
- GPT-4o: 64.0% success, displaying balanced retrieval and motion efficiency.
- DeepSeek-V3: 62.67% success, main amongst open-weight fashions.
- Remark: Most fashions excelled at question duties however struggled with action-based duties requiring protected multi-step execution.
What Errors Did Fashions Make?
Two dominant failure patterns emerged:
- Instruction adherence failures — invalid API calls or incorrect JSON formatting.
- Output mismatch — offering full sentences when structured numerical values have been required.
These errors spotlight gaps in precision and reliability, each crucial in medical deployment.
Abstract
MedAgentBench establishes the primary large-scale benchmark for evaluating LLM brokers in real looking EHR settings, pairing 300 clinician-authored duties with a FHIR-compliant setting and 100 affected person profiles. Outcomes present sturdy potential however restricted reliability—Claude 3.5 Sonnet v2 leads at 69.67%—highlighting the hole between question success and protected motion execution. Whereas constrained by single-institution information and EHR-focused scope, MedAgentBench gives an open, reproducible framework to drive the subsequent era of reliable healthcare AI brokers
Try the PAPER and Technical Weblog. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and information engineering, Michal excels at reworking complicated datasets into actionable insights.

