

Speech-to-Textual content, sometimes called Automated Speech Recognition (ASR), is a know-how that makes use of machine studying to transform human speech into textual content. It is a frequent know-how that many people encounter day-after-day – consider Siri, Okay Google, or any speech dictation software program.
What’s Automated Speech Recognition?
Automated Speech Recognition or ASR, entails utilizing Machine Studying to show spoken phrases into written textual content. This area has seen great development within the final decade, with ASR programs turning into a typical function in on a regular basis functions like TikTok and Instagram for reside captions, Spotify for podcast transcripts, Zoom for assembly notes, and plenty of others.
How Does Automated Speech Recognition Work?
Conventional Acoustic Speech Recognition Fashions:
Most ASR voice know-how begins with an acoustic mannequin to symbolize the connection between audio indicators and the fundamental constructing blocks of phrases. Acoustic fashions are a sort of statistical mannequin used to transform spoken language, which is within the type of an audio sign, right into a sequence of linguistic models, sometimes phonemes, phrases, or subword models. Conventional ASR programs contain a multi-step course of, together with language modeling and pronunciation dictionaries.
Finish-to-Finish Deep Studying Fashions
The Finish-to-Finish Automated Speech Recognition (ASR) mannequin is a revolutionary strategy within the area of speech know-how. Not like acoustic ASR programs, which contain a number of intermediate steps akin to phoneme recognition and language modeling, the Finish-to-Finish ASR mannequin goals to straight convert spoken language into textual content in a single step. It achieves this utilizing superior deep studying strategies, usually leveraging architectures like convolutional neural networks (CNNs) or transformer-based fashions. This streamlined strategy presents a number of benefits, together with better simplicity, improved accuracy, and the flexibility to deal with various accents and talking types extra successfully.
Why you must you employ the most effective speech to textual content fashions with Clarifai?
Clarifai, a number one AI platform, presents a compelling answer with its state-of-the-art Finish-to-Finish Automated Speech Recognition (ASR) fashions.
Here is why you must think about using greatest speech to textual content fashions by means of Clarifai’s API.
- State-of-the-Artwork ASR Fashions: Clarifai’s integration of top-tier ASR fashions ensures that you’ve got entry to probably the most superior and correct speech-to-text conversion know-how obtainable. These fashions are meticulously skilled on huge datasets, making them exceptionally proficient in changing spoken phrases into written textual content with excessive precision.
- Ease of Integration: Clarifai’s Speech to textual content(STT) fashions may be effortlessly built-in into your functions utilizing the API. Whether or not you are a seasoned developer or simply beginning, this ease of integration reduces the technical challenges and overhead, permitting you to focus in your core aims.
- Value-Efficient: Clarifai’s STT APIs can be found at a really aggressive worth level. This affordability opens the door for companies of all sizes and people to entry cutting-edge speech-to-text know-how with out breaking the financial institution.
- Knowledge Safety and Privateness: Clarifai locations a robust emphasis on knowledge safety and privateness. You possibly can belief that your audio knowledge is dealt with with the utmost care, making certain compliance with knowledge safety laws.
ASR Fashions
Clarifai comprises massive quantities of state-of-the-art Speech-to-Textual content fashions within the platform which can be utilized for a number of functions. Few of the most well-liked fashions are:
Chirp: Common speech mannequin (USM)
Chirp is a state-of-the-art speech mannequin with 2B parameters skilled on 12 million hours of speech and 28 billion sentences of textual content, spanning 300+ languages. This 2 billion-parameter speech mannequin developed by means of self-supervised coaching on in depth audio and textual content knowledge in over 100 languages. It boasts a formidable 98% accuracy in English and over 300% enchancment in varied languages with fewer than 10 million audio system.
Chirp’s uniqueness lies in its coaching strategy. Initially, it discovered from thousands and thousands of hours of unsupervised audio knowledge throughout a number of languages after which fine-tuned itself with restricted supervised knowledge for every language. This strategy contrasts with conventional speech recognition strategies that rely closely on language-specific supervised knowledge.
Key Outcomes
USM mannequin, fine-tuned on YouTube Captions knowledge, performs exceptionally effectively in 73 languages, with a mean phrase error fee of lower than 30%, surpassing Whisper by 32.7%. The USM mannequin additionally reveals decrease phrase error charges on varied ASR duties, akin to CORAAL, SpeechStew, and FLEURS. USM excels in high quality in comparison with Whisper in speech translation duties throughout completely different language segments based mostly on useful resource availability.

Check out Chirp mannequin right here https://clarifai.com/gcp/speech-recognition/fashions/chirp-asr
Meeting AI
AssemblyAI’s Speech-to-Textual content mannequin, often known as Conformer-2, represents the newest development in automated speech recognition. It’s skilled on an intensive dataset comprising 1.1 million hours of English audio knowledge. Conformer-2 builds upon its predecessor, Conformer-1, by providing substantial enhancements in dealing with correct nouns, alphanumerics, and robustness to noisy audio.
The Conformer-2 is a speech recognition mannequin based mostly on the Transformer structure with added convolutional layers for improved dependency seize. It presents wonderful modeling capabilities. The Conformer-2 goals to create an environment friendly speech recognition mannequin whereas sustaining the Conformer’s robust modeling capabilities.
Conformer-2 builds on the unique launch of Conformer-1, enhancing each mannequin efficiency and velocity. Conformer-1 mannequin achieved state-of-the-art efficiency (earlier outcomes).
Key Outcomes:
Conformer-2 maintains parity with Conformer-1 when it comes to phrase error fee however takes a step ahead in lots of person oriented metrics. Conformer-2 achieves a 31.7% enchancment on alphanumerics, a 6.8% enchancment on Correct Noun Error Price, and a 12.0% enchancment in robustness to noise. These enhancements have been made attainable by each rising the quantity of coaching knowledge to 1.1M hours of English audio knowledge (170% of the scale of information in comparison with Conformer-1) and rising the variety of fashions used to pseudo label knowledge.

Check out Meeting AI ASR mannequin right here: https://clarifai.com/assemblyai/speech-recognition/fashions/audio-transcription
Whisper-large
Whisper ASR mannequin, notable for its robustness and accuracy in English speech recognition. Whisper-Giant is skilled on a large-scale weakly supervised dataset that features 680,000 hours of audio, protecting 96 languages. The dataset additionally consists of 125,000 hours of X→en translation knowledge. The fashions skilled on this dataset switch effectively to present datasets zero-shot, eradicating the necessity for any dataset-specific fine-tuning to attain high-quality outcomes. Mannequin excels in dealing with accents, background noise, and technical language. It is able to transcription in a number of languages and translating them into English.
Whisper could not outperform specialised fashions on benchmarks like LibriSpeech, it excels in zero-shot efficiency throughout various datasets, making 50% fewer errors than different fashions. Whisper’s power lies in its massive and various dataset, roughly one-third of Whisper’s audio dataset is non-English, and it successfully learns speech-to-text translation, surpassing supervised state-of-the-art fashions in CoVoST2 to English translation zero-shot duties.
Check out Whisper-large mannequin right here: https://clarifai.com/openai/transcription/fashions/whisper
How one can Use Speech-To-Textual content mannequin with Clarifai
You possibly can entry and run the speech-to-text Mannequin utilizing Clarifai’s Python shopper.
Try the Code Under for the Whisper Mannequin:
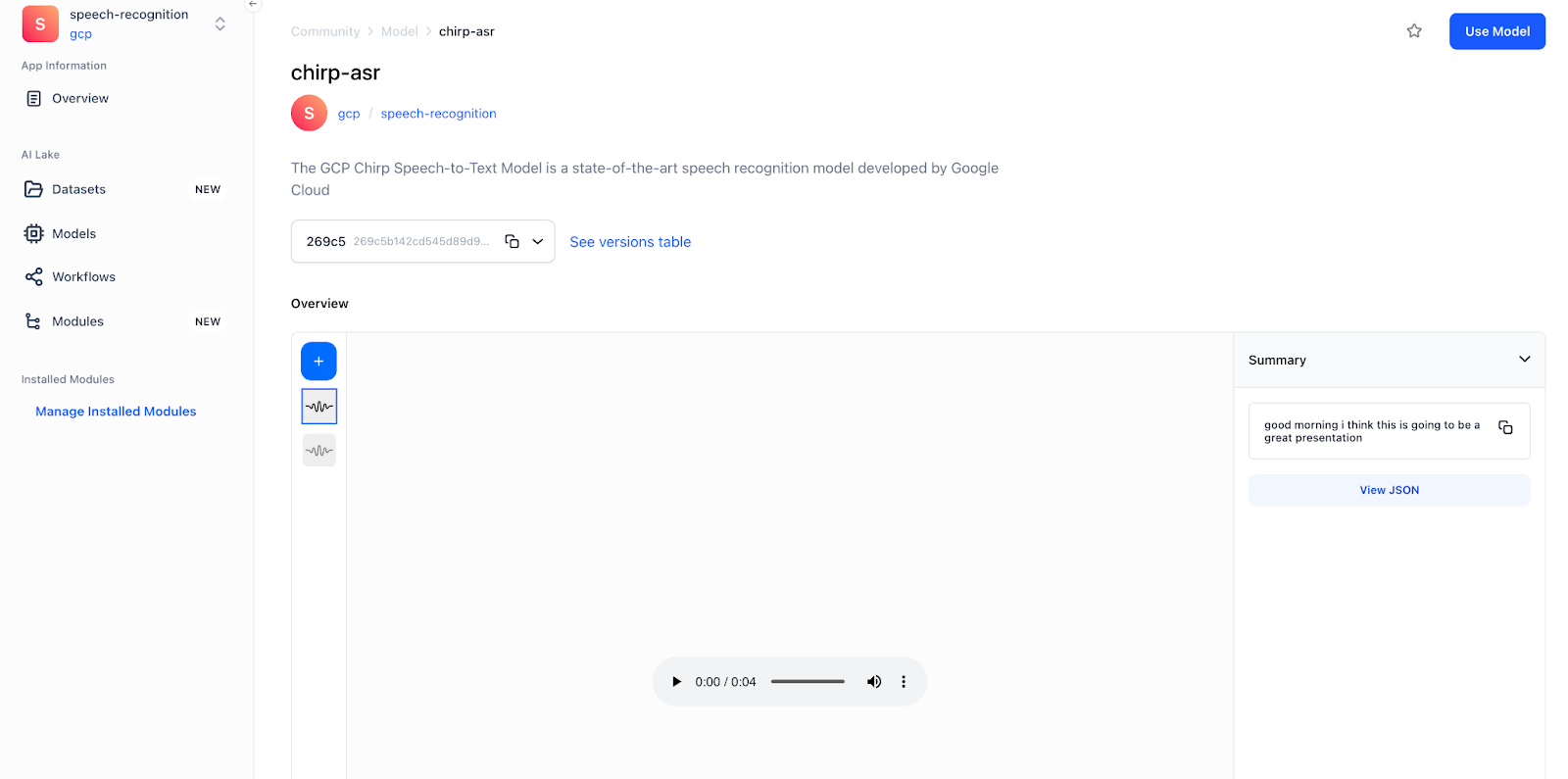
Mannequin Demo within the Clarifai Platform
Check out the gcp-chirp, assembly-audio-transcription, whisper-large fashions
Evaluating ASR Mannequin
Evaluating an Automated Speech Recognition (ASR) mannequin is a essential step in assessing its efficiency and making certain its effectiveness in changing spoken language into textual content precisely. The analysis course of sometimes entails varied metrics and strategies to measure the mannequin’s high quality. Listed below are some key features and strategies for evaluating ASR fashions:
- Phrase Error Price (WER): WER measures the accuracy of the acknowledged phrases within the system’s output in comparison with the reference or floor fact transcription. It quantifies the variety of errors when it comes to phrase substitutions, insertions, and deletions made by the ASR system.
Here is how WER is calculated:
Substitutions (S): This represents the variety of phrases within the reference transcription which are incorrectly changed by phrases within the ASR output.
Insertions (I): Insertions depend the variety of further phrases current within the ASR output that aren’t within the reference transcription.
Deletions (D): Deletions point out the variety of phrases within the reference transcription which are lacking within the ASR output.The method for calculating WER is as follows:
Phrase Error Price = (inserts + deletions + substitutions ) / variety of phrases in reference transcript
Merely put, this method offers us the proportion of phrases that the ASR tousled. A decrease WER, subsequently, means a better accuracy.
- Character Error Price (CER): Just like WER, CER measures the variety of character-level errors within the acknowledged textual content in comparison with the reference textual content. It supplies a finer-grained analysis, particularly helpful for languages with advanced scripts.
- Accuracy: This metric calculates the proportion of appropriately acknowledged phrases or characters within the transcription. It’s a easy measure of ASR mannequin accuracy.
What’s automated speech recognition used for?
Speech-to-Textual content Fashions can be utilized for varied speech recognition duties, together with transcription of audio recordings, voice instructions, and speech-to-text translation. These fashions may be utilized to completely different languages and accents, making it helpful for multilingual functions.
- Closed Captions: Producing closed captions is the obvious place to start out. Whether or not it’s for motion pictures, tv, video video games, or another type of media, offline ASR precisely creates captions forward of time to help comprehension and make media extra accessible to the deaf and hard-of-hearing.
- Content material Creation: Content material creators can profit from correct transcription to provide captions, subtitles, and written content material from spoken materials.
- Transcription Providers: Speech-to-Textual content mannequin is appropriate for varied transcription wants, together with changing audio recordings, interviews, conferences, and video content material into written textual content.
- Name Facilities: Name facilities are additionally using ASR to drive higher buyer outcomes. Makes use of embrace monitoring buyer assist interactions, analyzing preliminary contacts to extra rapidly resolve points, and enhancing worker coaching.
Checkout the platform right here, and do not hesitate to join with us for any questions or thrilling concepts you wish to share.

