
There was a noticeable pattern in Synthetic Common Intelligence (AGI) techniques towards utilizing pre-trained, adaptable representations, which give task-agnostic benefits in numerous functions. Pure language processing (NLP) is an effective instance of this tendency since subtle fashions show flexibility with thorough information overlaying a number of domains and duties with simple directions. The recognition of NLP encourages a complementary technique in laptop imaginative and prescient. Distinctive obstacles come up from the need for broad perceptual capacities in common illustration for numerous vision-related actions. Whereas pure language processing (NLP) focuses totally on textual content, laptop imaginative and prescient has to deal with complicated visible information reminiscent of traits, masked contours, and object placement. In laptop imaginative and prescient, attaining common illustration necessitates skillful dealing with of assorted difficult duties organized in two dimensions, as proven in Determine 1.
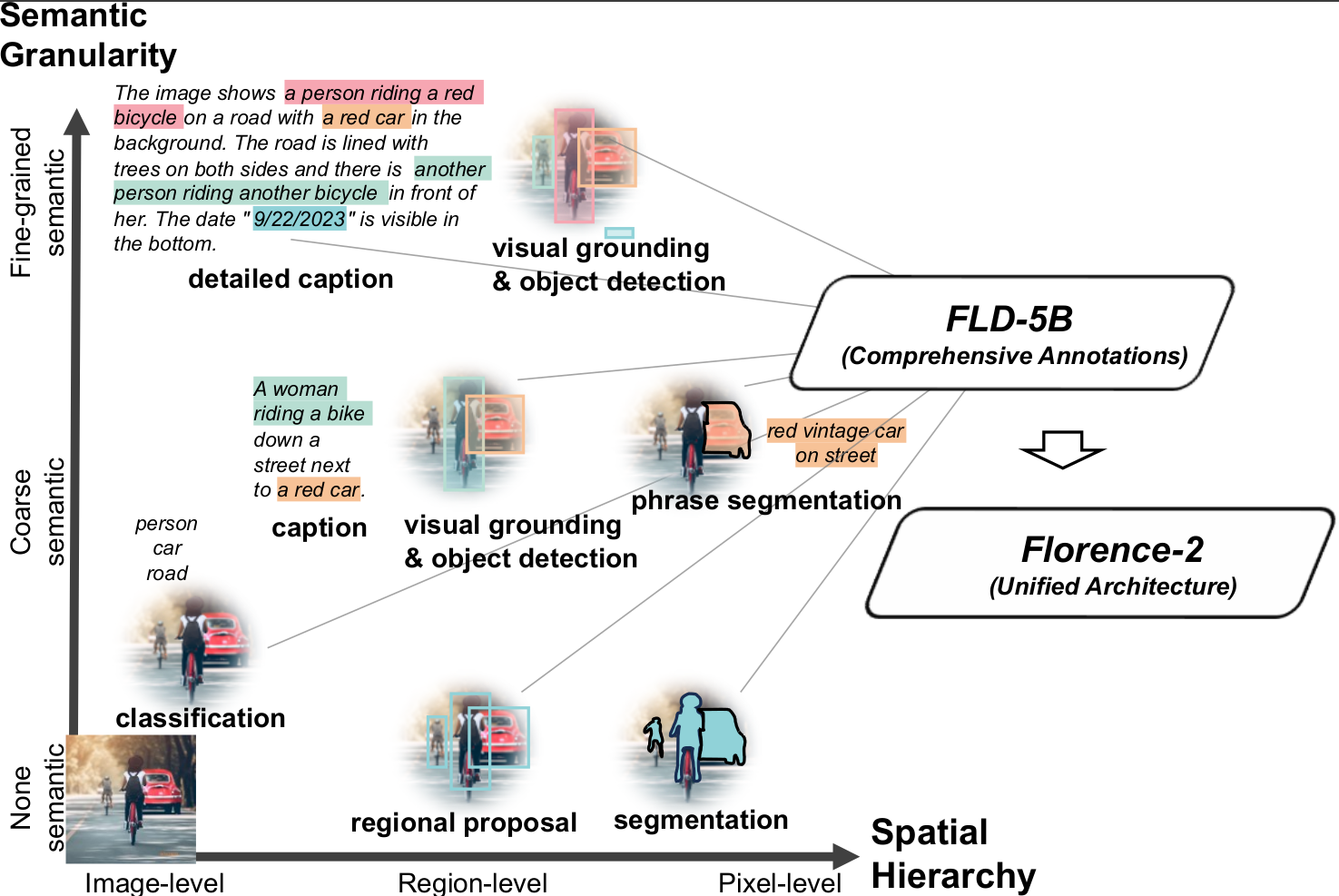
Determine 1
Spatial Hierarchy: The mannequin has to acknowledge spatial data at completely different sizes, comprehending fine-grained pixel particulars and image-level concepts. To help the complicated spatial hierarchy in imaginative and prescient, the mannequin have to be able to managing a variety of granularities.
Semantic Granularity: In laptop imaginative and prescient, common illustration ought to cowl a variety of semantic granularities. The paradigm strikes from summary titles to extra detailed explanations, offering versatile comprehension for numerous makes use of.
This pursuit is characterised by distinctiveness and substantial challenges. A key hurdle is the necessity for extra, hindering the event of a foundational mannequin able to capturing the intricate nuances of spatial hierarchy and semantic granularity. Present datasets, reminiscent of ImageNet, COCO, and Flickr30k Entities, tailor-made for specialised functions, are extensively labeled by people. To beat this constraint, it’s crucial to generate intensive annotations for every picture on a bigger scale. One other problem is the absence of a that seamlessly integrates spatial hierarchy and semantic granularity in laptop imaginative and prescient. With task-specific design, conventional fashions carry out nicely in duties like semantic segmentation, object identification, and film captioning. Nevertheless, creating a whole, cohesive mannequin that may alter to completely different imaginative and prescient duties in a task-independent means is essential, even taking up new duties with little to no task-specific fine-tuning.
Via unified pre-training and community design, the mannequin pioneers the combination of spatial, temporal, and multi-modal options in laptop imaginative and prescient. The primary evolutionary iteration excels in switch studying by way of task-specific fine-tuning utilizing custom-made adapters and pre-training with noisy text-image pairings. Nevertheless, its reliance on huge task-specific datasets and adapters ends in gaps in terms of tackling the 2 main points talked about above. On this work, researchers from Azure present a common spine that’s attained utilizing multitask studying with wealthy visible annotations. This results in a prompt-based, unified illustration for numerous imaginative and prescient duties, which efficiently tackles the problems of incomplete complete information and lack of a uniform structure.
Giant-scale, high-quality annotated information is critical for multitask studying. Relatively than relying on time-consuming human annotation, their information engine creates an intensive visible dataset named fld, which has 5.4B annotations for 126M photographs. There are two efficient processing modules on this engine. The primary module departs from the standard single and handbook annotation technique through the use of specialised fashions to annotate photographs collectively and autonomously. Much like the knowledge of crowds concept, many fashions collaborate to create a consensus, leading to a extra neutral and reliable image interpretation. Utilizing primary fashions which were realized, the second module repeatedly refines and filters these computerized annotations.
Their mannequin makes use of a sequence-to-sequence (seq2seq) structure, integrating a picture encoder and a multi-modality encoder-decoder by leveraging this massive dataset. This structure helps a variety of imaginative and prescient duties with out requiring task-specific architectural changes, in keeping with the NLP group’s objective of versatile mannequin creation with a uniform basis. Each annotation within the dataset is persistently standardized into textual outputs. This permits the constant optimization of a single multitask studying technique utilizing the identical loss perform because the objective. The end result is a versatile imaginative and prescient basis mannequin, or mannequin, that may deal with a variety of features, together with object recognition, captioning, and grounding, all beneath the management of a single mannequin with standardized parameters. Textual prompts are utilized to activate duties, according to the methodology employed by massive language fashions (LLMs).
Their methodology achieves a common illustration and has wide-ranging use in lots of visible duties. Key findings encompass:
- The mannequin is a versatile imaginative and prescient basis mannequin that gives new state-of-the-art zero-shot efficiency in duties, together with referencing expression comprehension on RefCOCO, visible grounding on Flick30k, and captioning on COCO.
- However its small dimension, it competes with extra specialised fashions after being fine-tuned utilizing publicly obtainable human-annotated information. Most notably, the improved mannequin units new benchmark state-of-the-art scores on RefCOCO.
- The pre-trained spine outperforms supervised and self-supervised fashions on downstream duties, COCO object detection and occasion segmentation, and ADE20K semantic segmentation. Their mannequin, which makes use of the Masks-RCNN, DINO, and UperNet frameworks, delivers vital will increase of 6.9, 5.5, and 5.9 factors on COCO and ADE20K datasets, respectively and quadruples the coaching effectivity of pre-trained fashions on ImageNet.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to hitch our 33k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and Electronic mail E-newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
For those who like our work, you’ll love our publication..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is enthusiastic about constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing initiatives.

