

Introduction
Generative transformer fashions characterize a breakthrough that has given rise to an period of generative AI. Because the launch of ChatGPT, the tech trade has witnessed an explosion of LLMs, particularly open-source ones. Companies of any dimension can faucet into the ability of those LLMs to create tailor-made options for his or her wants, whether or not it is creating chatbots, producing content material, or analyzing knowledge. That will help you navigate this panorama, we’ve crafted a curated record of the Prime 10 Giant Language Fashions in 2023. Let’s discover them!
The findings are summarized within the under desk:
| Mannequin Household Title | Created By | Sizes | Kind | License |
| Llama 2 | Meta | 7B, 13B, 70B | Basis | Industrial |
| Falcon | Expertise Innovation Institute | 7B, 40B | Basis | Industrial |
| RedPajama | Collectively, Ontocord.ai, ETH DS3Lab, CRFM Stanford Hazy Analysis group. | 3B, 7B | Basis | Industrial |
| Mistral | Mistral AI | 7B | Basis | Industrial |
| MPT | Mosaic ML | 7B | Basis | Industrial |
| X Gen | Salesforce AI | 7B | Basis | Industrial |
| Dolly V2 | Databricks | 12B | Basis | Industrial |
| Zephyr | Hugging Face | 7B | High-quality-Tuned | Industrial |
| Code Llama | Meta | 7B, 13B, 34B | High-quality-Tuned | Industrial |
| WizardLM | Can Xu | 13B, 70B | High-quality-Tuned |
Llama 2
Llama 2 is a household of huge language fashions launched by Meta. Llama 2 builds upon the success of Llama 1 and incorporates a number of enhancements to reinforce its efficiency and security. These fashions are designed to excel in advanced reasoning duties throughout numerous domains, making them appropriate for analysis and industrial use.
Llama-2 is educated on a big corpus of publicly accessible knowledge and fine-tuned to align with human preferences, making certain usability and security. The fashions are optimized for dialogue use circumstances and can be found in a variety of parameter sizes, together with 7B, 13B, and 70B.
Llama 2-Chat is a fine-tuned model of Llama-2 fashions which can be optimized for dialogue use circumstances. These fashions are particularly designed to generate human-like responses to pure language enter, making them appropriate for chatbot and conversational AI functions.
Along with the usual Llama-2 fashions, the Llama 2-Chat fashions are additionally fine-tuned on a set of security and helpfulness benchmarks to make sure that they generate applicable and helpful responses. This consists of measures to stop the fashions from producing offensive or dangerous content material and to make sure that they supply correct and related info to customers.
The context window size within the Llama-2 mannequin is 4096 tokens. That is an enlargement from the context window size of the 2048 tokens used within the earlier model of the mannequin, Llama-1. The longer context window permits the mannequin to course of extra info, which is especially helpful for supporting longer histories in chat functions, numerous summarization duties, and understanding longer paperwork.
Check out the chat variations of Llama 2 fashions right here: Llama-2 70 b Chat, Llama-2 13 B Chat, Llama-2 7B chat
Falcon
Falcon is a household of state-of-the-art language fashions created by the Expertise Innovation Institute. The Falcon household consists of two base fashions: Falcon-40B and Falcon-7B and was educated on the RefinedWeb dataset.
The structure of Falcon was optimized for efficiency and effectivity. Combining high-quality knowledge with these optimizations, Falcon considerably outperforms GPT-3 for less than 75% of the coaching compute finances and requires a fifth of the compute at inference time.
The Falcon fashions incorporate an fascinating characteristic known as multi-query consideration. Not like the standard multi-head consideration scheme, which has separate question, key, and worth embeddings per head, multi-query consideration shares a single key and worth throughout all consideration heads. This enhances the scalability of inference, considerably lowering reminiscence prices and enabling optimizations like statefulness. The smaller Okay, V-cache throughout autoregressive decoding contributes to those advantages.
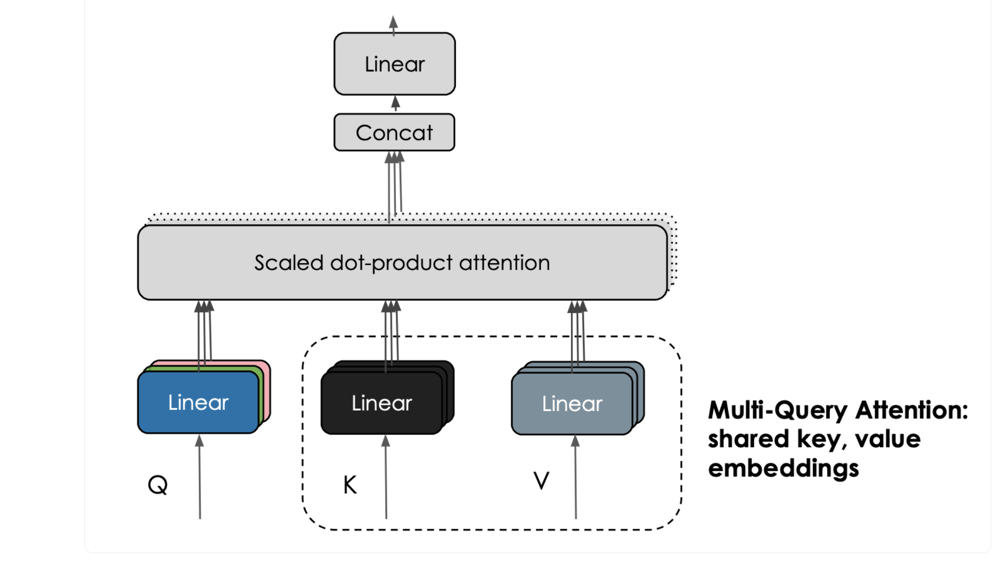
Falcon additionally has the Instruct variations, Falcon-40b-Instruct and Falcon-7b-Instruct that are fine-tuned on directions and conversational knowledge, they thus lend higher to widespread assistant-style duties.
Check out the fashions right here: Falcon-40b-Instruct, Falcon-7b-Instruct
RedPajama
RedPajama is a collaborative challenge involving Collectively and leaders from the open-source AI neighborhood together with Ontocord.ai, ETH DS3Lab, AAI CERC, Université de Montréal, MILA – Québec AI Institute, Stanford Middle for Analysis on Basis Fashions (CRFM), Stanford Hazy Analysis analysis group and LAION.
RedPajama Base Fashions: The three billion parameter and seven billion parameter base fashions type the inspiration of the RedPajama fashions. They had been developed based mostly on the Pythia structure and designed to excel in several duties
Two variations of RedPajama-3b-base are RedPajama-INCITE-Chat-3B-v1 and RedPajama-INCITE-Instruct-3B-v1. The RedPajama-INCITE-Chat-3B-v1 mannequin is optimized for conversational AI duties, adept at producing human-like textual content in a conversational context. Then again, the RedPajama-INCITE-Instruct-3B-v1 mannequin is designed to observe directions successfully, making it very best for understanding and executing advanced directions.
Equally, the 7b base variant has RedPajama-INCITE-Chat-7B-v1 and RedPajama-INCITE-Instruct-7B-v1.
Check out the mannequin right here: RedPajama-INCITE-Chat-7B-v1
Mistral 7B
Mistral 7B is the language mannequin from Mistral AI. It represents a big leap in pure language understanding and era. The mannequin is launched beneath the Apache 2.0 license, permitting its unrestricted utilization and it makes use of Grouped-query consideration (GQA) to allow quicker inference, making it appropriate for real-time functions. Moreover, Sliding Window Consideration (SWA) is employed to deal with longer sequences effectively and economically.
Mistral 7B surpasses the efficiency of Llama 2 13B on all benchmark duties and excels on many benchmarks in comparison with Llama 34B. It additionally demonstrates aggressive efficiency with CodeLlama-7B on code-related duties whereas sustaining proficiency in English language duties.
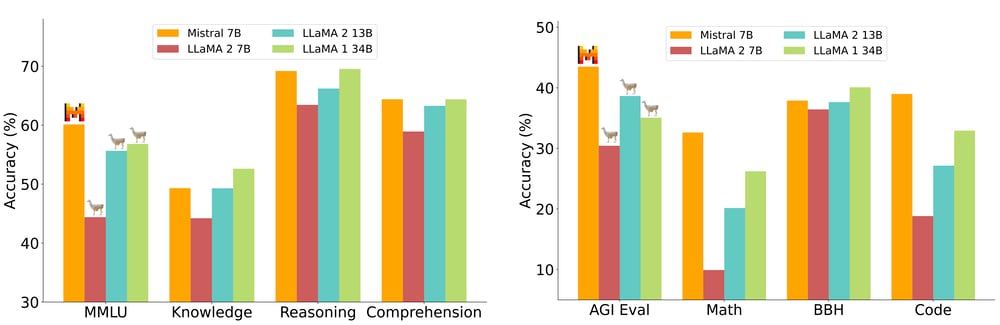
Mistral 7B additionally excels not solely in code-related duties, approaching CodeLlama 7B efficiency, but additionally stays extremely proficient in numerous English language duties.
The mannequin could be simply fine-tuned on any process. Mistral 7B Instruct is the mannequin fine-tuned for chat, which outperforms Llama 2 13B chat.
Check out the mannequin right here: Mistral 7B Instruct
MPT 7B
MPT is an open-source transformer mannequin collection designed by MosaicML. The fashions are educated on 1T tokens that may deal with extraordinarily lengthy inputs and are additionally optimized for quick coaching and inference.
There are three fine-tuned fashions along with the bottom MPT-7B that are MPT-7B-Instruct, MPT-7B-Chat, and MPT-7B-StoryWriter-65k+. Listed here are extra particulars of those fashions:
- MPT-7B Base: MPT-7B Base is a decoder-style transformer with 6.7B parameters. It was educated on 1T tokens of textual content and code that was curated by MosaicML’s knowledge crew. This base mannequin consists of FlashAttention for quick coaching and inference and ALiBi for finetuning and extrapolation to lengthy context lengths.
- MPT-7B-StoryWriter-65k+: MPT-7B-StoryWriter-65k+ is a mannequin designed to learn and write tales with super-long context lengths. It was constructed by finetuning MPT-7B with a context size of 65k tokens on a filtered fiction subset of the books3 dataset. At inference time, because of ALiBi, MPT-7B-StoryWriter-65k+ can extrapolate even past 65k tokens, and we’ve demonstrated generations so long as 84k tokens on a single node of A100-80GB GPUs.
- MPT-7B-Instruct: MPT-7B-Instruct is a mannequin for short-form instruction following. Constructed by finetuning MPT-7B on a dataset we additionally launch, derived from Databricks Dolly-15k and Anthropic’s Useful and Innocent datasets.
- MPT-7B-Chat: MPT-7B-Chat is a chatbot-like mannequin for dialogue era. Constructed by finetuning MPT-7B on ShareGPT-Vicuna, HC3, Alpaca, Useful and Innocent, and Evol-Instruct datasets.
Check out the Mannequin right here: MPT-7B-Instruct
XGen 7B
XGen 7B is a collection of 7B LLMs from Salesforce AI. The XGen-7b fashions are educated utilizing JaxFormer, which leverages environment friendly coaching of LLMs beneath each knowledge and mannequin parallelism optimized for TPU-v4 {hardware}.
XGen-7B-4K-base which is educated for 800B tokens with a sequence size of 2k tokens first, then for one more 400B tokens (whole 1.2T tokens) with 4k and XGen-7B-8K-base initialized with XGen-7B-4K-base and additional educated for 300B extra tokens (whole 1.5T tokens) with 8K sequence size.
XGen-7B additionally has 4K and 8K instruct variations that are fine-tuned on public area tutorial knowledge together with databricks-dolly-15k, oasst1, Baize and GPT-related datasets.
The XGEN-7B-8K-instruct mannequin is educated on as much as 8K sequence size for as much as 1.5 trillion tokens, making it appropriate for lengthy sequence modeling duties comparable to textual content summarization, dialogue era, and code era.
Check out 8K Instruct mannequin right here: X-Gen-7B-8K-instruct
Dolly V2
The Dolly V2 mannequin is a 12B parameter language mannequin developed by Databricks, constructed upon the EleutherAI Pythia mannequin household. It’s designed to observe directions supplied in pure language and generate responses accordingly. Not like its predecessor, Dolly 2.0 is an open-source mannequin, fine-tuned on a high-quality human-generated instruction dataset known as “databricks-dolly-15k” licensed for analysis and industrial use.
The databricks-dolly-15k dataset incorporates 15,000 high-quality human-generated immediate/response pairs particularly designed for instruction tuning massive language fashions.
The first goal of this mannequin is to exhibit human-like interactivity whereas adhering to supplied directions.
Check out the Dolly V2 right here: Dolly V2-12 B
Zephyr-7B-Alpha
Zephyr is a collection of language fashions designed to function useful assistants. Zephyr-7B-alpha is the primary mannequin on this collection and represents a fine-tuned model of Mistral 7B. It was educated on a mixture of publicly accessible and artificial datasets utilizing Direct Choice Optimization (DPO) to enhance its efficiency. The mannequin outperformed Llama-2-70B Chat on MT Bench.
Zephyr-7B-alpha was initially fine-tuned on a variant of the UltraChat dataset, which incorporates artificial dialogues generated by ChatGPT. Additional alignment was achieved utilizing huggingface TRL’s DPOTrainer on the openbmb/UltraFeedback dataset, consisting of prompts and mannequin completions ranked by GPT-4. This permits the mannequin for use for chat functions.
Zephyr-7B-alpha has not been aligned to human preferences utilizing strategies like Reinforcement Studying from Human Suggestions (RLHF), nor has it undergone in-the-loop filtering of responses like ChatGPT. Consequently, it could produce outputs that could be problematic, particularly when deliberately prompted.
Check out the mannequin right here: Zephyr-7B-Alpha
Code Llama
Code Llama is a state-of-the-art LLM from Meta able to producing code, and pure language about code, from each code and pure language prompts. It can be used for code completion and debugging. It helps lots of the hottest languages getting used right this moment, together with Python, C++, Java, PHP, Typescript (Javascript), C#, and Bash.
Code Llama is a code-specialized model of Llama 2 that was created by additional coaching Llama 2 on its code-specific datasets. Code Llama options enhanced coding capabilities, constructed on prime of Llama 2.
Code Llama is on the market in three sizes 7B, 13B, and 34B parameters respectively. Every of those fashions is educated with 500B tokens of code and code-related knowledge.
Moreover, there are two further variations that are fine-tuned variations of Code Llama that are Code Llama-Python which is fine-tuned on 100B tokens of Python code and Code Llama-Instruct which is an instruction fine-tuned and aligned variation of Code Llama.
Check out the Code Llama Instruct fashions: Code Llama-34b-Instruct, Code Llama-13b-Instruct, Code Llama-7b-Instruct
WizardLM
WizardLM fashions are language fashions fine-tuned on the Llama2-70B mannequin utilizing Evol Instruct strategies. Regardless of WizardLM lagging behind ChatGPT in some areas, the findings recommend that fine-tuning LLMs with AI-evolved directions holds nice promise for enhancing these fashions.
Evol-Instruct is a technique for creating an enormous quantity of instruction knowledge with various complexity ranges utilizing LLMs. It begins with a set of preliminary directions and progressively transforms them into extra intricate varieties. Evol-Instruct avoids the guide crafting of open-domain instruction knowledge which is a time-consuming and labor-intensive course of.
There are totally different variations of WizardLM fashions, WizardLM-70B, WizardLM-13B and WizardLM-7B that are fine-tuned on AI-evolved directions utilizing the Evol+ strategy. The mannequin is pre-trained on a big corpus of textual content knowledge and fine-tuned on the Llama-2 dataset to generate high-quality responses to advanced directions.
Check out the WizardLM fashions right here: Wizard LM 70B, Wizard LM 13B
LLM Battleground
Evaluate numerous LLMs without delay and see which works finest in your usecase. LLM Battleground Module permits you to run and evaluate quite a few LLMs concurrently, offering an unprecedented platform for comparability. The module enormously simplifies the method of LLM choice with options like centralized entry, simultaneous testing, real-time comparability, and communal testing insights.
Check out the Module right here: LLM Battleground Module
Conclusion
We have explored a variety of cutting-edge fashions, together with Llama 2, Falcon, Mistral 7B, MPT and extra. These fashions present the exceptional developments within the area of Generative AI. Every of them brings distinctive strengths, making them appropriate for a wide selection of functions, from chatbot performance to textual content era, summarization, and past.
That is merely the beginning of an thrilling journey, with additional developments anticipated within the area of LLMs, particularly within the open-source neighborhood. The months forward promise much more thrilling improvements that can proceed to form the panorama of AI, providing new prospects and alternatives.

