
Sponsored Content material
At the moment, AI is in all places, and generative AI is being touted as its killer app. We’re seeing massive language fashions (LLMs) like ChatGPT, a generative pre-trained transformer, being utilized in new and inventive methods.
Whereas LLMs have been as soon as relegated to highly effective cloud servers, round-trip latency can result in poor person experiences, and the prices to course of such massive fashions within the cloud are rising. For instance, the price of a search question, a standard use case for generative AI, is estimated to extend by ten occasions in comparison with conventional search strategies as fashions change into extra advanced. Foundational general-purpose LLMs, like GPT-4 and LaMDA, utilized in such searches, have achieved unprecedented ranges of language understanding, technology capabilities, and world information whereas pushing 100 billion parameters.
Points like privateness, personalization, latency, and rising prices have led to the introduction of Hybrid AI, the place builders distribute inference between units and the cloud. A key ingredient for profitable Hybrid AI is the fashionable devoted AI engine, which might deal with massive fashions on the edge. For instance, the Snapdragon® 8cx Gen3 Compute Platform powers many units with Home windows on Snapdragon and options the Qualcomm® Hexagon™ NPU for operating AI on the edge. Together with instruments and SDKs, which give superior quantization and compression strategies, builders can add hardware-accelerated inference to their Home windows apps for fashions with billions of parameters. On the similar time, the platform’s always-connected functionality through 5G and Wi-Fi 6 supplies entry to cloud-based inference nearly wherever.
With such instruments at one’s disposal, let’s take a better take a look at Hybrid AI, and how one can reap the benefits of it.
Hybrid AI
Hybrid AI leverages the very best of native and cloud-based inference to allow them to work collectively to ship extra highly effective, environment friendly, and extremely optimized AI. It additionally runs easy (aka mild) fashions domestically on the gadget, whereas extra advanced (aka full) fashions might be run domestically and/or offloaded to the cloud.
Builders choose totally different offload choices primarily based on mannequin or question complexity (e.g., mannequin measurement, immediate, and technology size) and acceptable accuracy. Different concerns embody privateness or personalization (e.g., conserving information on the gadget), latency and obtainable bandwidth for acquiring outcomes, and balancing vitality consumption versus warmth technology.
Hybrid AI gives flexibility by way of three normal distribution approaches:
- System-centric: Fashions which give enough inference efficiency on information collected on the gadget are run domestically. If the efficiency is inadequate (e.g., when the tip person is just not happy with the inference outcomes), an on-device neural community or arbiter might resolve to dump inference to the cloud as a substitute.
- System-sensing: Gentle fashions run on the gadget to deal with easier inference instances (e.g., automated speech recognition (ASR)). The output predictions from these on-device fashions are then despatched to the cloud and used as enter to full fashions. The fashions then carry out further, advanced inference (e.g., generative AI from the detected speech information) and transmit outcomes again to the gadget.
- Joint processing: Since LLMs are reminiscence certain, {hardware} typically sits idle ready as information is loaded. When a number of LLMs are wanted to generate tokens for phrases, it may be useful to speculatively run LLMs in parallel and offload accuracy checks to an LLM within the cloud.
A Stack for the Edge
A robust engine and growth stack are required to reap the benefits of the NPU in an edge platform. That is the place the Qualcomm® AI Stack, proven in Determine 1, is available in.
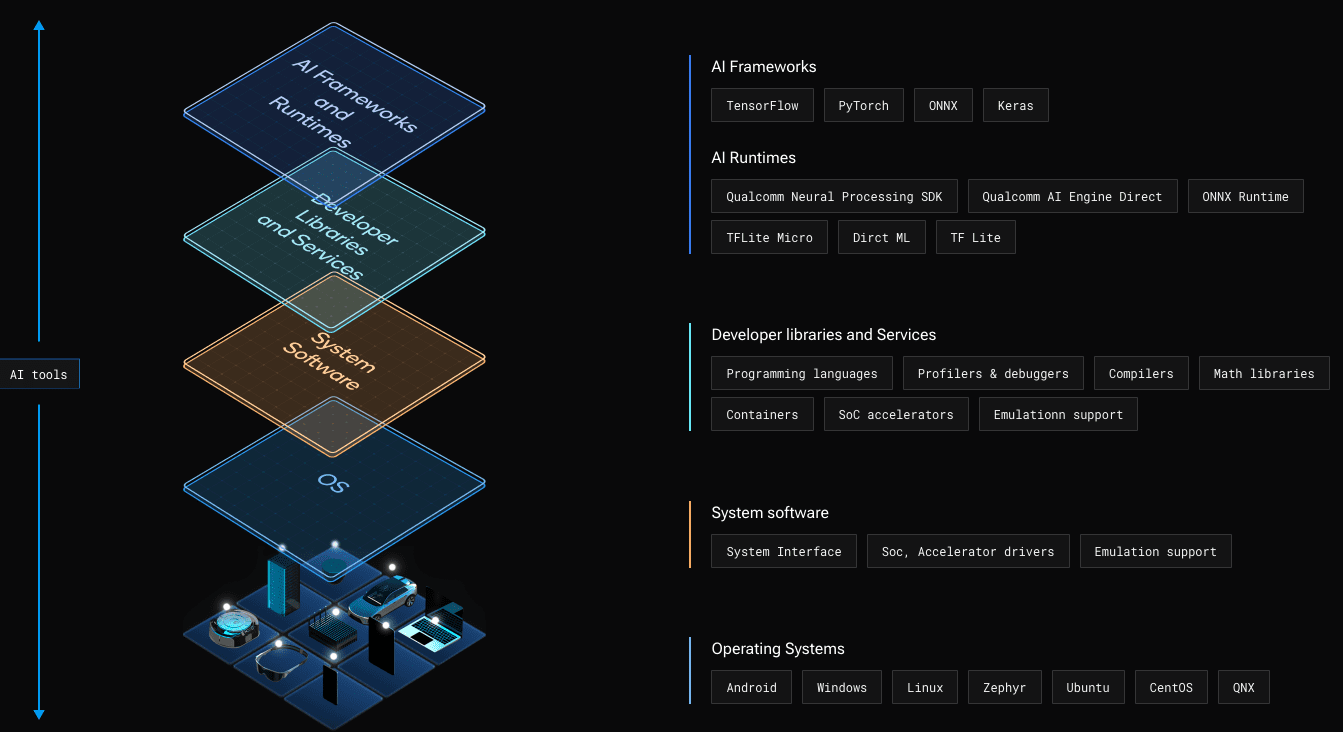
Determine 1 – The Qualcomm® AI Stack supplies {hardware} and software program parts for AI on the edge throughout all Snapdragon platforms.
The Qualcomm AI Stack is supported throughout a variety of platforms from Qualcomm Applied sciences, Inc., together with Snapdragon Compute Platforms which energy Home windows on Snapdragon units and Snapdragon Cell Platforms which energy a lot of right now’s smartphones.
On the stack’s highest stage are standard AI frameworks (e.g., TensorFlow) for producing fashions. Builders can then select from a few choices to combine these fashions into their Home windows on Snapdragon apps. Observe: TFLite and TFLite Micro are usually not supported for Home windows on Snapdragon.
The Qualcomm® Neural Processing SDK for AI supplies a high-level, end-to-end answer comprising a pipeline to transform fashions right into a Hexagon particular (DLC) format and a runtime to execute them as proven in Determine 2.
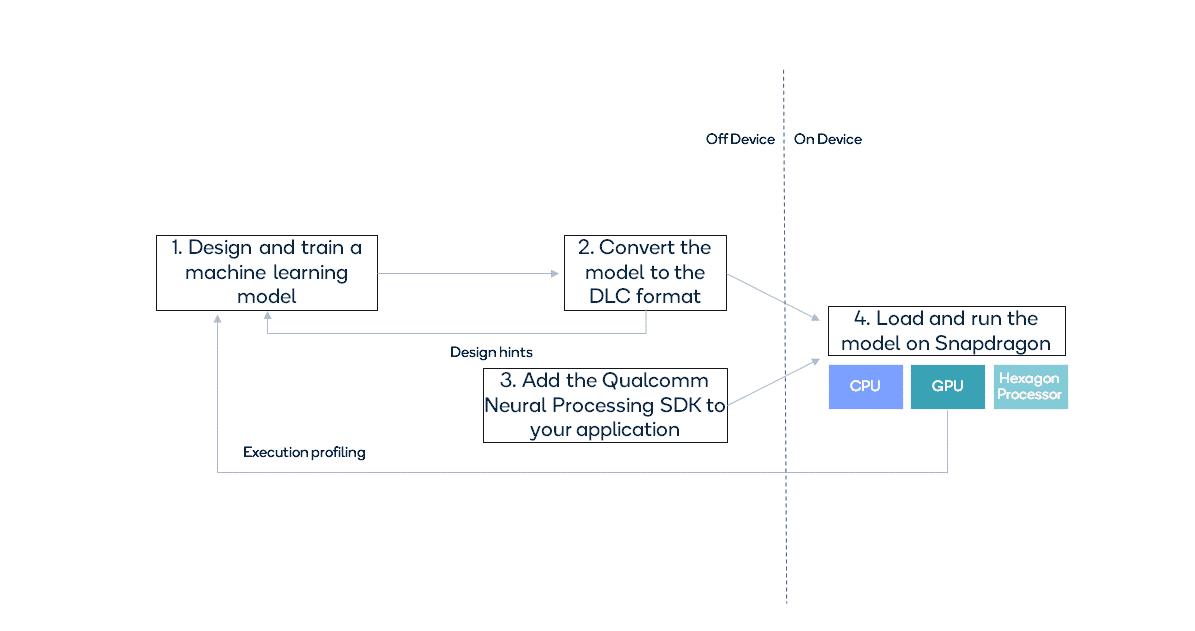
Determine 2 – Overview of utilizing the Qualcomm® Neural Processing SDK for AI.
The Qualcomm Neural Processing SDK for AI is constructed on the Qualcomm AI Engine Direct SDK. The Qualcomm AI Engine Direct SDK supplies lower-level APIs to run inference on particular accelerators through particular person backend libraries. This SDK is turning into the popular technique for working with the Qualcomm AI Engine.
The diagram under (Determine 3) exhibits how fashions from totally different frameworks can be utilized with the Qualcomm AI Engine Direct SDK.
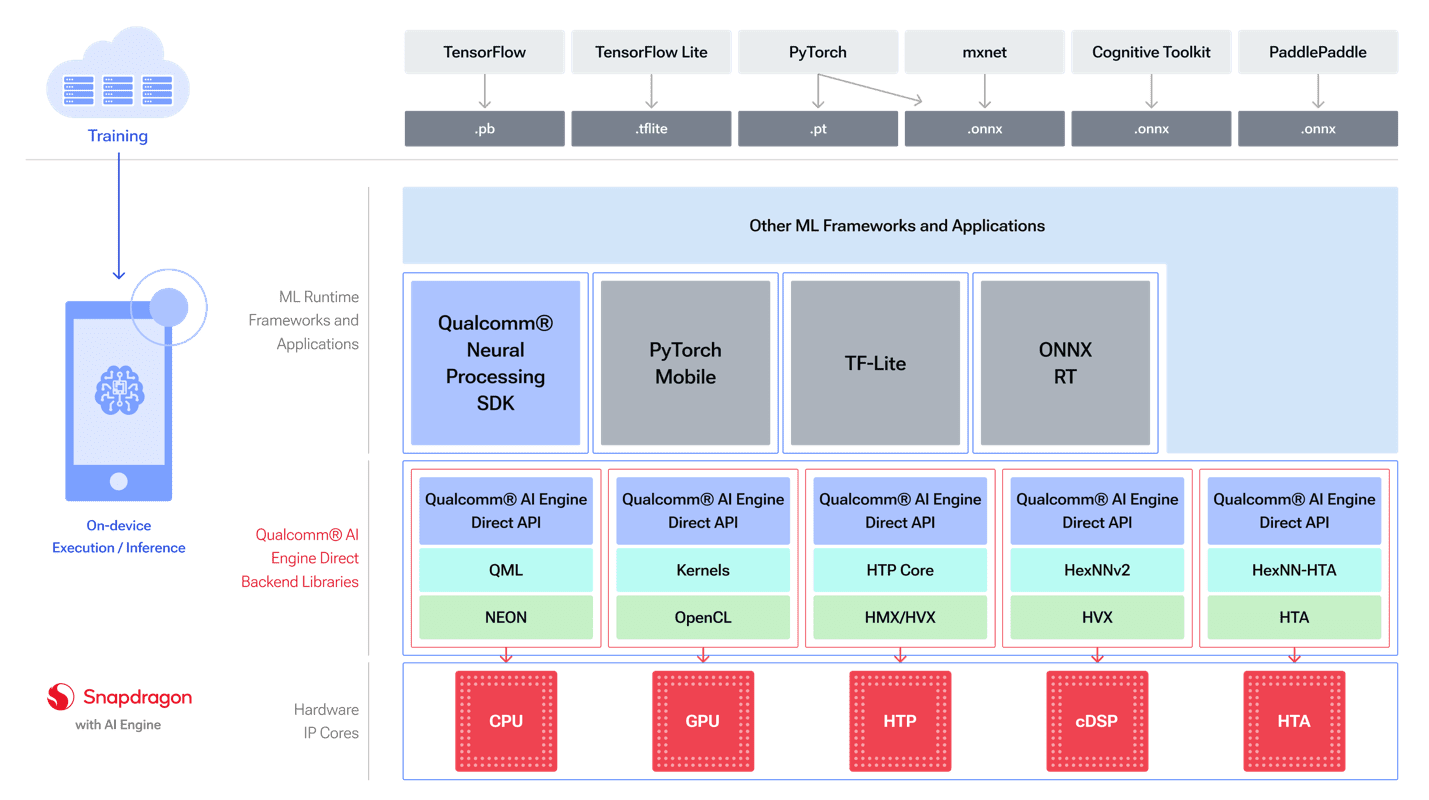
Determine 3 – Overview of the Qualcomm AI Stack, together with its runtime framework assist and backend libraries.
The backend libraries summary away the totally different {hardware} cores, offering the choice to run fashions on essentially the most acceptable core obtainable in numerous variations of Hexagon NPU (HTP for the Snapdragon 8cx Gen3).
Determine 4 exhibits how builders work with the Qualcomm AI Engine Direct SDK.
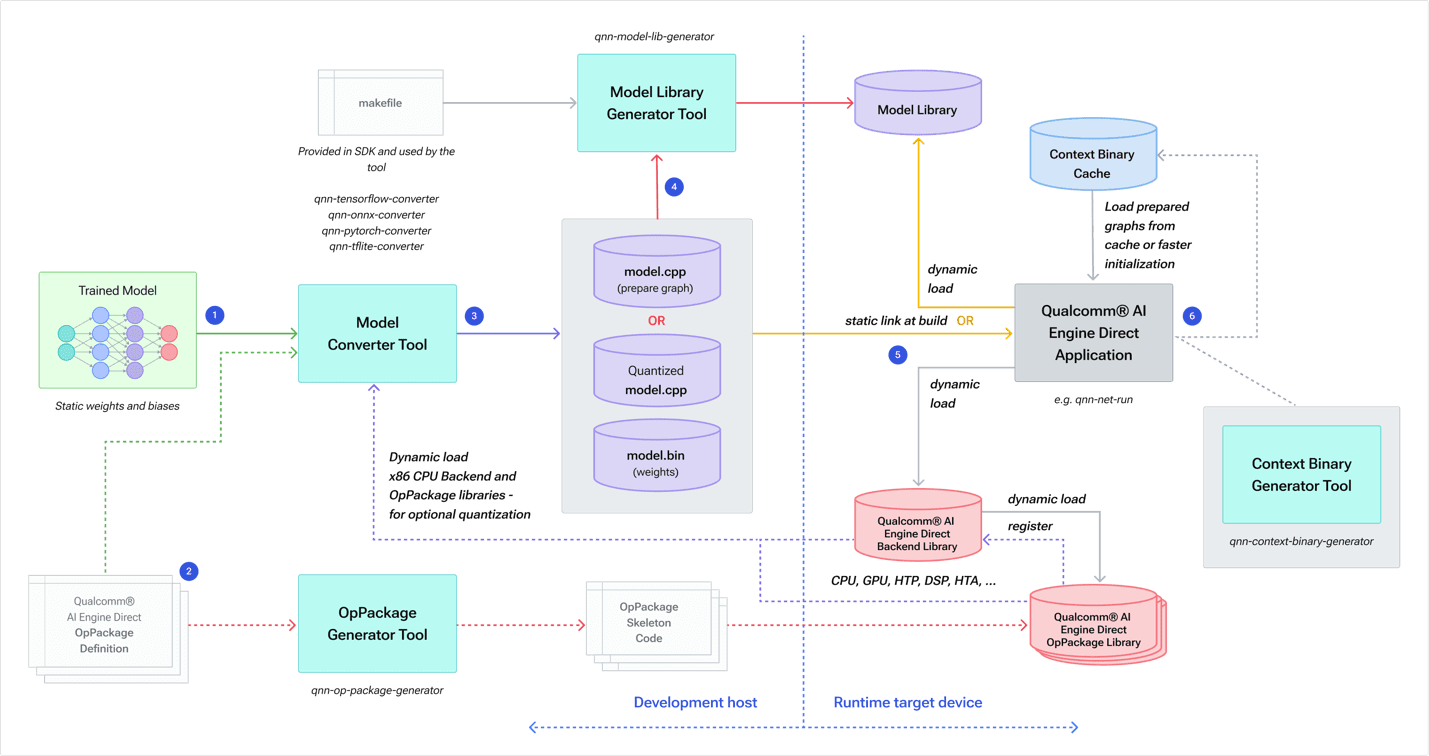
Determine 4 – Workflow to transform a mannequin right into a Qualcomm AI Engine Direct illustration for optimum execution on Hexagon NPU.
A mannequin is skilled after which handed to a framework-specific mannequin conversion device, together with any non-obligatory Op Packages containing definitions of customized operations. The conversion device generates two parts:
- mannequin.cpp containing Qualcomm AI Engine Direct API calls to assemble the community graph
- mannequin.bin (binary) file containing the community weights and biases (32-bit floats by default)
Observe: Builders have the choice to generate these as quantized information.
The SDK’s generator device then builds a runtime mannequin library whereas any Op Packages are generated as code to run on the goal.
You’ll find implementations of the Qualcomm AI Stack for a number of different Snapdragon platforms spanning verticals comparable to cellular, IoT, and automotive. This implies you possibly can develop your AI fashions as soon as, and run them throughout these totally different platforms.
Study Extra
Whether or not your Home windows on Snapdragon app runs AI solely on the edge or as a part of a hybrid setup, you should definitely take a look at the Qualcomm AI Stack web page to study extra.
Snapdragon and Qualcomm branded merchandise are merchandise of Qualcomm Applied sciences, Inc. and/or its subsidiaries.

