
The introduction of Pre-trained Language Fashions (PLMs) has signified a transformative shift within the area of Pure Language Processing. They’ve demonstrated distinctive proficiency in performing a variety of language duties, together with Pure Language Understanding (NLU) and Pure Language Era (NLG). These fashions sometimes incorporate thousands and thousands and even billions of parameters, resulting in substantial computational and reminiscence necessities. Nevertheless, the appreciable computational and reminiscence wants of those fashions current important challenges, as acknowledged by the analysis group.
On this paper, the authors introduce a novel quantization framework often known as LoRA-Nice-Tuning-aware Quantization (LoftQ). This framework is particularly tailor-made for pre-trained fashions that necessitate quantization and LoRA fine-tuning. The framework actively combines low-rank approximation, working along side quantization to collectively approximate the unique high-precision pre-trained weights.
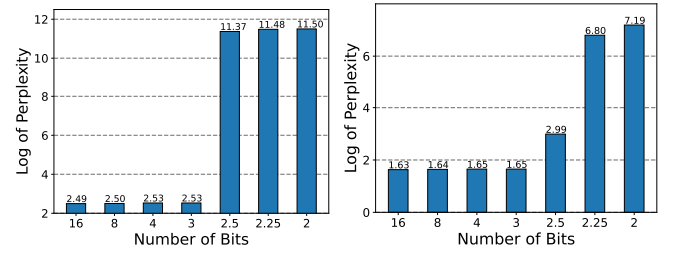
The above picture demonstrates QLoRA efficiency with completely different bits. Left: QLoRA initialization of LLAMA-2-13b on WikiText-2. Proper: Apply QLoRA to LLAMA-2-13b on WikiText-2 language modelling job. Smaller perplexity signifies higher efficiency.
Quantization Strategies. We apply two quantization strategies to display LoftQ is appropriate with completely different quantization features:
• Uniform quantization is a basic quantization technique. It uniformly divides a steady interval into 2N classes and shops an area most absolute worth for dequantization.
• NF4 and its 2-bit variant NF2 are quantization strategies utilized in QLoRA. They assume that the high-precision values are drawn from a Gaussian distribution and map these values to discrete slots which have equal chance.
We carry out 2-bit and 4-bit quantization on all fashions, reaching compression ratios of 25-30% and 15-20% on the 4-bit and 2-bit ranges, respectively. All of the experiments are carried out on NVIDIA A100 GPUs.
The analysis of their quantization framework is carried out by in depth experiments on numerous downstream duties, together with NLU, query answering, summarization, and NLG. The outcomes of those experiments display that LoftQ constantly surpasses QLoRA throughout all precision ranges. For instance, with 4-bit quantization, they attain a 1.1 and 0.8 enchancment in Rouge-1 for XSum and CNN/DailyMail, respectively. As the sector of NLP continues to advance, it’s anticipated that additional improvements and optimizations will assist bridge the hole between the immense potential of PLMs and their sensible deployment, benefiting a variety of functions and customers.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t overlook to affix our 31k+ ML SubReddit, 40k+ Fb Group, Discord Channel, and Electronic mail E-newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you happen to like our work, you’ll love our publication..
We’re additionally on WhatsApp. Be a part of our AI Channel on Whatsapp..
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming knowledge scientist and has been working on this planet of ml/ai analysis for the previous two years. She is most fascinated by this ever altering world and its fixed demand of people to maintain up with it. In her pastime she enjoys touring, studying and writing poems.

