
To speak with others, people can solely use a restricted quantity of phrases to elucidate what they see within the exterior world. This adaptable cognitive potential reveals that the semantic info communicated by way of language is intricately interwoven with completely different types of sensory enter, notably for imaginative and prescient. Based on neuroscientific investigations, amodal semantic representations are shared throughout visible and linguistic experiences. For instance, the phrase “cat” generates conceptual info corresponding to a cat’s psychological picture. Nevertheless, the semantic relationships between conceptual classes and the sleek transition between V&L modalities have solely generally been quantified or realized utilizing computational fashions.
Latest analysis on neural decoders confirmed that visible content material will be recreated from representations of the visible cortex captured through purposeful magnetic resonance imaging. Nevertheless, the blurriness and semantic meaninglessness or mismatch of the rebuilt photos continued. Alternatively, the neuroscience group has offered sturdy proof to again the declare that the VC of the mind can entry semantic concepts in each V&L kinds. The outcomes compel us to develop new “thoughts studying” gear to translate what you understand vocally. Such an effort has appreciable scientific worth in illuminating cross-modal semantic integration mechanisms and will provide helpful info for augmentative or restorative brain-computer interfaces.
The authors from Zhejiang College introduce MindGPT, a non-invasive neural language decoder that converts the blood-oxygen-level-dependent patterns produced by static visible stimuli into well-formed phrase sequences, as seen in Fig. 1 Left. To their information, Tang et al. first tried to create a non-invasive neural decoder for perceived speech reconstruction that may even recuperate the that means of silent movies for the non-invasive language decoder. Nevertheless, as a result of fMRI has a poor temporal decision, a lot fMRI knowledge should be gathered to foretell the fine-grained semantic significance between the candidate phrases and the induced mind responses.
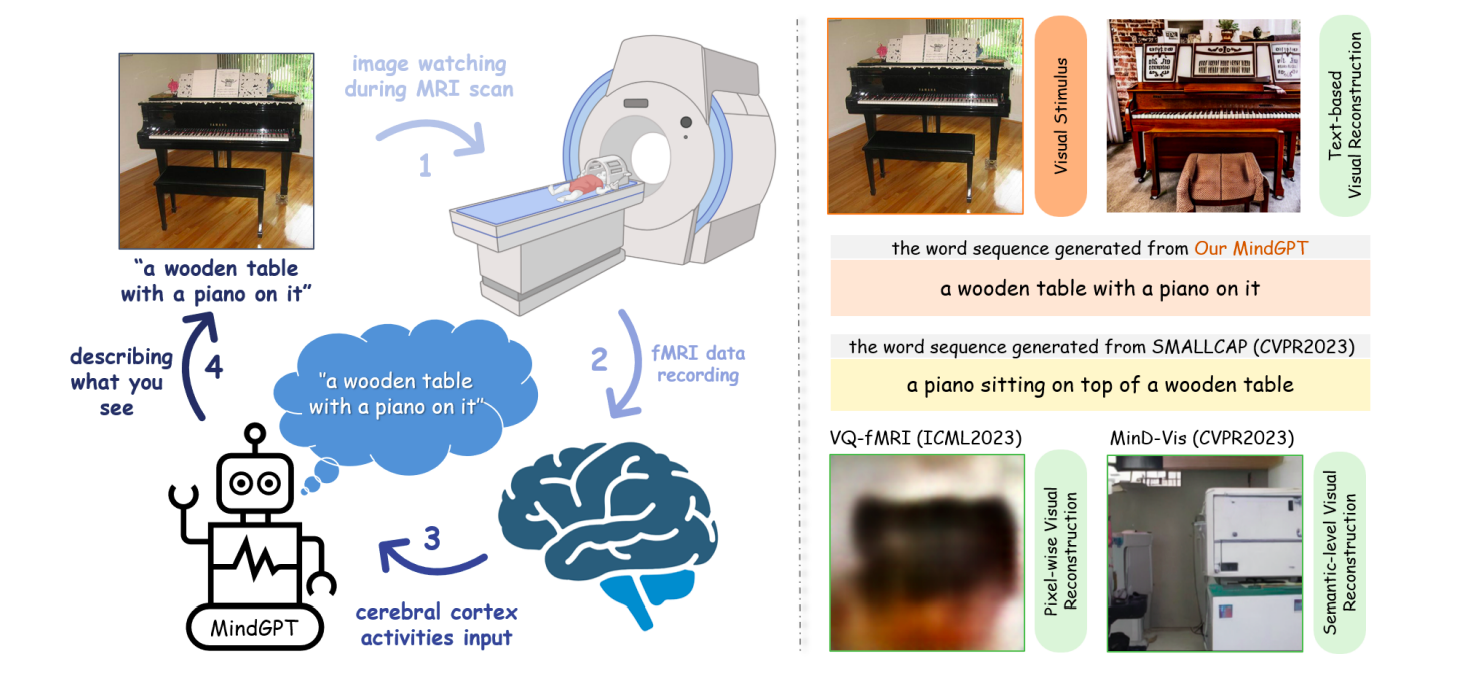
Determine 1: Left: The MindGPT non-intrusive language decoder’s general pipeline. Proper: The outcomes of our MindGPT reconstruction, the SMALLCAP picture captioning mannequin, and the VQ-fMRI and MinD-Vis visible decoding approaches.
As an alternative, this analysis focuses on whether or not and to what diploma amodal language maps are semantically labeled by static visible sensory experiences, similar to a single picture. Their MindGPT is constructed to fulfill two essential necessities: (i) it should be capable to extract visible semantic representations from mind exercise, and (ii) it should embrace a technique for changing discovered VSRs into correctly constructed phrase sequences. They first determined to make use of an enormous language mannequin, GPT-2, as their textual content generator. This mannequin has been pre-trained on a dataset of thousands and thousands of internet sites known as WebText, and it permits us to restrict sentence patterns to resemble well-formed pure English.
Then, to shut the that means hole between brain-visual linguistic representations end-to-end, they undertake a simple but efficient CLIP-guided fMRI encoder with cross-attention layers. This neural decoding formulation has a really low variety of learnable parameters, making it each light-weight and environment friendly. They’ve proven on this work that the MindGPT could function a hyperlink between the mind’s VC and machine for dependable V&L semantic transformations. Their approach has discovered generalizable mind semantic representations and a radical comprehension of B & V & L modalities for the reason that language it produces precisely captures the visible semantics of the noticed inputs.
As well as, they found that even with little or no fMRI image coaching knowledge, the well-trained MindGPT seems to emerge with the capability to document visible cues of stimulus pictures, which makes it simpler for us to analyze how visible options contribute to language semantics. Additionally they observed, with assistance from a visualization device, that the latent mind representations taught by MindGPT had useful locality-sensitive traits in each low-level visible facets and high-level semantic concepts, according to sure findings from the sphere of neuroscience. Total, their MindGPT revealed that, in distinction to earlier work, it’s doable to infer the semantic relationships between V&L representations from their mind’s VC with out contemplating the temporal decision of fMRI.
Take a look at the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to affix our 31k+ ML SubReddit, 40k+ Fb Neighborhood, Discord Channel, and E-mail Publication, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
When you like our work, you’ll love our e-newsletter..
We’re additionally on WhatsApp. Be a part of our AI Channel on Whatsapp..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at present pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is captivated with constructing options round it. He loves to attach with folks and collaborate on attention-grabbing initiatives.

